由链表问题引发对堆、栈的讨论
刚听到链表其实还是有些惧怕的,我记得第一次见链表是在高中的时候,那时见到一个简单的Demo还读不懂,思路更是模糊。直到在大学课本上才真正对链表有了深入的了解,但由于大学老师一笔带过的授课,我并没有刻意关注链表这东西。
前几天,Sheldon Zhong 就一些关于链表的问题与我讨论,几经引用和修改最终整出个马马虎虎的Demo。
#include <iostream>
using namespace std;
class Node{
private:
int value;
Node * next;
public:
Node(){ }
Node * getNext() { return this->next; }
void setNext(Node * p) { this->next = p; }
int getValue() { return this->value; }
void setValue(int value) { this->value = value; }
};
class LinkedList{
private:
Node * head;
public:
LinkedList() {
head = NULL;
Node one;
one.setNext(NULL);
one.setValue(0);
head = &one;
cout << "head address in construction: " << head << endl;
cout << "head next address in construction: " << head->getNext() << endl;
}
void add(int value);
};
void LinkedList::add(int value)
{
Node * p;
cout << "head address in add (previous): " << head << endl;
cout << "head next address in add (previous): " << head->getNext() << endl;
p = head;
cout << "head address in add (current): " << head << endl;
cout << "head next address in add (current): " << head->getNext() << endl;
cout << "p address in add (current): " << p << endl;
cout << "p next address in add (current): " << p->getNext() << endl;
// do something...
}
int main()
{
LinkedList a;
a.add(50);
return 0;
}
但运行的结果却有些诡异(以至于某人认为编译器坏了)。
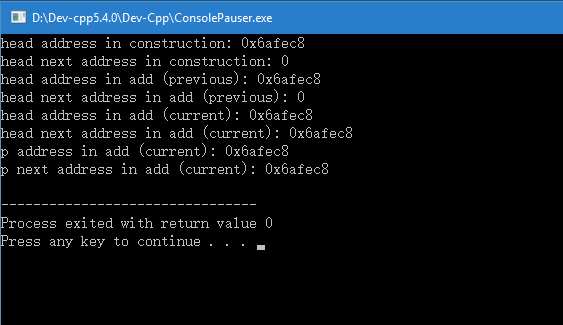
观察LinkedList类内的add函数,可以看到我们只是将head指针给了p指针,没有改变head和head->next的指向,而结果却显示next指向已改变。
void LinkedList::add(int value)
{
Node * p;
cout << "head address in add (previous): " << head << endl;
cout << "head next address in add (previous): " << head->getNext() << endl;
p = head;
cout << "head address in add (current): " << head << endl;
cout << "head next address in add (current): " << head->getNext() << endl;
cout << "p address in add (current): " << p << endl;
cout << "p next address in add (current): " << p->getNext() << endl;
// do something...
}
我们尝试给Node类添加构造函数,并将LinkedList类构造函数中的(Node one;)定义为全局,结果却意外的正常了。
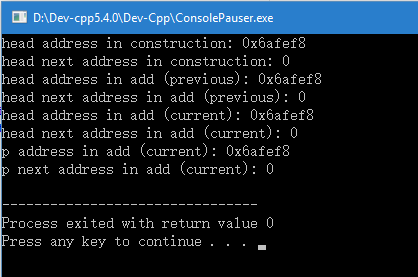
回过头看看构造函数,我们定义了一个Node对象,但作用域是在构造函数中,当构造函数结束后会被回收释放,我们初步认为是作用域问题,但后来我们尝试将LinkedList类构造函数中新建head节点(Node)的代码移动到add函数中,错误依旧。我们渐渐把矛头指向Node对象是否被系统回收释放上,最终的结果印证了我们的猜想。
我们将定义Node对象的语句从
Node one;
one.setValue(0);
one.setNext(NULL);
head = &one;
更改为
Node * one = new Node();
one->setValue(0);
one->setNext(NULL);
head = one;
无论放在构造函数中还是放在add函数中,结果均正确。我们了解到定义对象主要有两种方式
- ClassName object(param); //在栈(Stack)中分配空间,由系统自动释放。
- ClassName *object = new ClassName(); //在堆(Heap)中分配空间,手动释放。
关于五大内存分区
- 栈(Stack),由编译器在需要的时候分配,在不需要的时候自动清除的变量存储区。里面的变量通常是局部变量、函数参数等。
- 堆(Heap),由new分配的内存块,它们的释放编译器不会处理,由我们的应用程序控制,一般一个new就要对应一个delete。如果程序员没有释放掉,那么在程序结束后,操作系统会自动回收。(new char; delete char;new char2[2]; delete char2;)
- 自由存储区,由malloc等分配的内存块,它和堆是十分相似的,不过它是用free来结束自己的生命的。
- 全局/静态存储区,全局变量和静态变量被分配到同一块内存中,在C语言中,全局变量又分为初始化的和未初始化的,在C++里面不再做这个区分,它们共同占用同一块内存区。
- 常量存储区,这是一块比较特殊的存储区,里面存放的是常量,不允许修改(当然,你要通过非正当手段也可以修改,而且方法很多,在《const的思考》一文中,有6种方法。
因此,垃圾回收是针对堆的,而栈因为本身是FILO(first in, last out.),即先进后出,能够自动释放。所以new创建的对象,都放到堆中,而之前使用第一种方法定义对象则在构造函数结束后被系统回收。
实际上,有关于堆和栈的认识我曾经在CnBlogs转载过一片文章,由于时间过去比较久,记忆不深刻,以至于没能意识到这微妙的区别。以后学习的路还很长,永远“Stay hungry, Stay foolish.”的心态。
