PHP 实现简单验证码识别
之前看过一些关于 PHP 实现验证码识别的文章,但一直没有所运用。后来某次偶然机会,我进行了一些尝试,第一次做到二分值就无法继续下去,第二次做到除噪就弃坑,直到我看到……
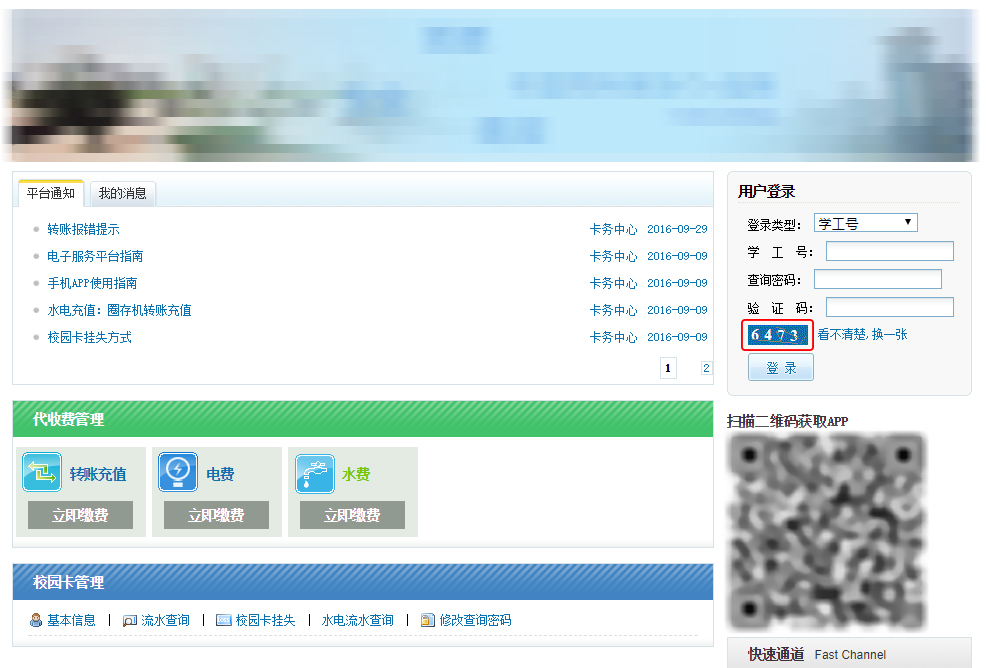
甚至移动端……
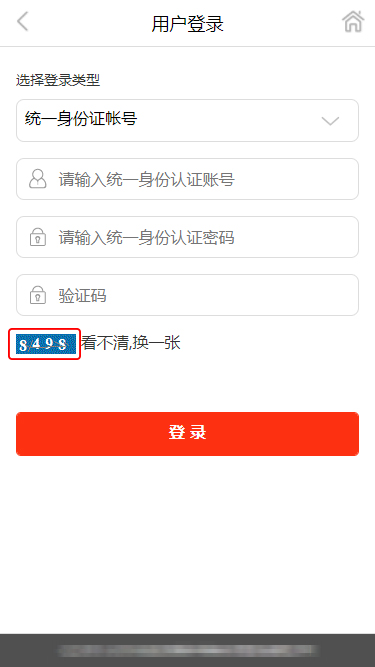
我发现某高校校园卡中心的 PC 端官网和移动端登录需要的验证码都是一个类型的。(因涉及某校网络安全,所以对部分内容进行了打码处理)
如此简单的验证码是否会对其安全有影响?所以我又进行了一次尝试,我将其记录下来,一方面是对学习知识的总结,以后能回看;另一方面希望对研究这方面技术的同学有所帮助;另外也希望引起站长的注意,在提供验证码时多些考虑加入干扰进去。由于以前没有接触过这方面的知识,初次尝试,理解浅显,犯错难免,欢迎纠正。
首先,部分人可能对验证码的作用不是特别了解,我这里就引用一段验证码的描述:
验证码的作用:能够有效防止黑客对某一个特定注册用户用特定程序暴力破解方式进行不断的登录尝试,以通过该方式猜到用户密码等信息。其实现代的验证码一般是防止机器批量注册的,例如防止机器批量发帖回复。目前,不少网站为了防止用户利用机器人自动注册、登录、灌水,都采用了验证码技术。
所谓验证码,就是将一串随机产生的数字、字母、符号,甚至是中文文字,生成一幅图片,图片里加上一些干扰像素(防止 OCR 识别),例如线、点、扭曲、阵格等,由用户肉眼识别其中的验证码信息,输入表单提交网站验证,验证成功后才能使用某项功能。目前,随着 OCR 识别技术的发展,这些随机数字、字母、符号和中文文字生成的图片容易被 OCR 识别,所以很多网站已经开始使用新式的验证技术——滑动验证或是拼图验证,国内提供该解决方案的其中一家公司——极验。
验证码识别一般分为以下几个步骤:
- 取出字模:由于各个网站的验证码各不相同,去字模时,我们需要多下载几张图片,使这些图片中,包括所有的字符,用来建立这个验证码的特征码库;
- 二值化:把图片上的验证数字上每个像素用 “1” 表示,其他部分用 “0” 表示;
- 除噪:去除干扰像素,即把孤立的有效的值去掉;
- 切割字符:把验证码图片中的每个字符单独提取出来;
- 对照样本:把字符特征码和提取的验证码进行对比,得到验证图片上的数字。
我们按照这些步骤对某高校校园卡中心网站的登录验证码进行识别。
1、取出字模
因为某高校校园卡中心网站的登录验证码只有数字,且仅包括 1-9 数字,所以首先我们只需要收集包括 1-9 的验证码图片。

我这里下载了 7 张验证码,当然尽量样本下载越多越好。我们选择其中一张,干扰线没有过多影响数字的验证码,用它来做二值化。

2、二值化
二值化我们希望将背景和干扰线统统用 “0” 表示,只将验证数字部分用 “1” 表示。我们需要知道颜色的三原色,即红绿蓝。所有的颜色都可以通过三原色的不同组合而产生一个颜色。那么二值化就是对红绿蓝三色进行一些条件过滤来完成二值化。
这时候我们可以用 PHP 中 gd 库获取图片每个像素的 RGB 值,将 RGB 值分别打印出来,也可以借助 Photoshop 的吸管工具来观察 RGB 值规律。
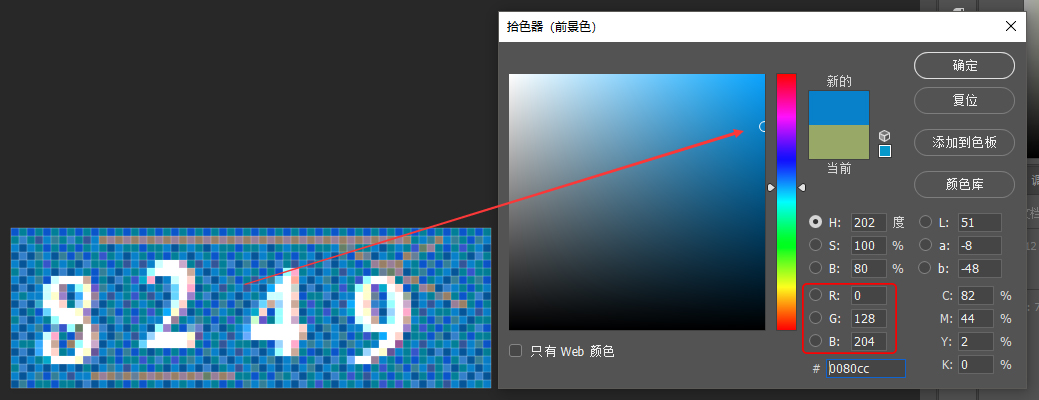
通过 Photoshop,我们观察到背景部分红色通道值均小于 52,绿色通道值等于 128 或 85。

接着处理干扰线与干扰点。其实取出干扰线的方法很简单,干扰线的一个重要特征是不能影响验证码的显示效果,所以制作干扰线时它的 RGB 可能低于或者高于某个特定值。还是通过 Photoshop 取色工具,观察干扰线和干扰点的 RGB 值。
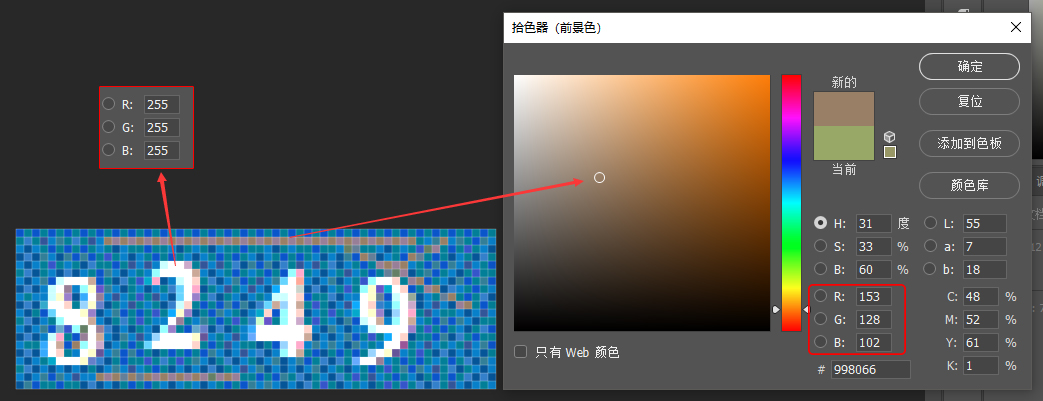
干扰线部分红色通道值和绿色通道值固定在 153 和 128,部分干扰点红色通道值为 153,绿色通道值为 170。同时,我们还注意到验证码数字部分及其周边部分像素点的各通道值,都至少有一个通道值大于 252。
因此,我们可以写出过滤条件:
$data[$i][$j] = 1;
if ($rgbarray['red'] <= 51)
$data[$i][$j] = 0;
if ($rgbarray['red'] <= 153 && $rgbarray['green'] == 128)
$data[$i][$j] = 0;
if ($rgbarray['red'] <= 153 && $rgbarray['green'] == 170)
$data[$i][$j] = 0;
if ($rgbarray['red'] >= 253 || $rgbarray['green'] >= 253 || $rgbarray['blue'] >= 253)
$data[$i][$j] = 1;
3、除噪
因为我们在上面分析背景部分的 RGB 颜色时一同分析了干扰点颜色,经过过滤后,发现我们二值化的结果很好,没有出现孤立的点。如果有出现,需要再优化过滤条件,使这些孤立的点被去除。

4、切割字符
我们就得到干净的二值化数据,接下来要做的就是切割字符。切割字符的方法有很多种,这里我采用最简单的一种,先垂直方向切割成为字符,然后在水平方向去掉多于的 0。

第一步切割红线部分,第二步切割黄线部分,这样就可以得到独立的字符了。切割出来后,如图:

5、对照样本
对照样本第一步就是如何取得样本,我们可以通过多次获取验证码,获得各个数字较少被干扰线干扰时的值。例如本例中我们取的这张验证码中,每个数字都刚好没有被干扰线影响。当然这种情况很难遇到,我们可以将多个切割后的值做成一个特征库。当识别时,将切割好后的值每行连接,形成一个字符串,并利用 PHP 函数 similar_text() 计算相似度,取最高相似度的 key,即为这个数字。
如本例中的 “8”,与我取得的 “8” 的特征码对比,得到如下相似度:
1: float(37.5)
2: float(29.545454545455)
3: float(73.863636363636)
4: float(59.090909090909)
5: float(80.681818181818)
6: float(31.818181818182)
7: float(20.238095238095)
8: float(93.181818181818)
9: float(54.545454545455)
可以很清晰的看出,它 “8” 的特征码相似度最大,所以我们推测它即为 “8”。通过遍历,我们可以将四位验证码计算出来。

换测试验证码后,仍然识别成功。

我们甚至可以将模拟登录也写上,测试识别后并模拟登录平台成功。
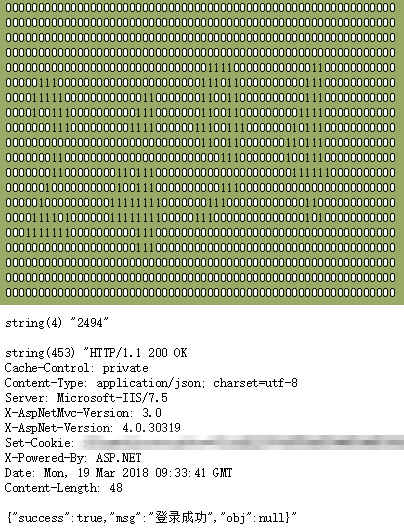
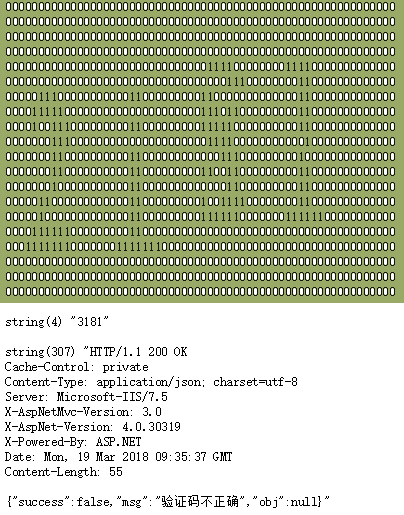
当然,由于我的样本较少,偶尔识别还是会出现失败的情况,以后还可以在这个基础上进行优化,也欢迎有兴趣的同学能给点优化建议。
代码已经开源到 Github,可移步至这里查看。

