Go 垃圾回收浅析
代码分析基于: go1.22.1
垃圾回收
垃圾回收(Garbage Collection / GC)是指一种自动的内存管理机制。当程序占用的一部分内存空间不再被访问时,垃圾回收器会根据特定的垃圾回收算法向操作系统归还这部分内存空间。垃圾回收器可以减轻程序员的负担,也减少程序中的错误。
回收器分类
引用计数
引用计数基本思路是给每个对象添加一个引用计数器,当有新的引用指向该对象时,计数器加1;当引用被移除时,计数器减1。当一个对象的引用计数器为0时,说明没有任何引用指向它,那么它就可以被视为垃圾,并被回收。
引用计数算法的优点是实现简单直观,并且不需要暂停整个应用程序。但它也有一些明显的缺点:
- 无法解决对象之间的循环引用问题。如果两个对象互相引用,它们的引用计数永远不会为0,导致无法被回收而发生内存泄漏。
- 需要编译器的支持,为每个对象分配引用计数器并在对象引用发生变化时更新计数器,会带来一定的额外开销。
- 在多线程环境下,需要对引用计数器进行加锁保护,增加了同步开销。
追踪回收
追踪式垃圾回收(Tracing Garbage Collection)是一种主流的垃圾回收算法,也被称为可达性分析算法(Reachability Analysis)。它的基本原理如下:
- 定义一组根节点对象(Root Set),通常包括全局变量、线程栈中的局部变量等。
- 从根节点开始,遍历所有可达的对象,即被根节点直接或间接引用的对象。这个遍历过程就是"追踪"的含义。
- 将遍历标记的对象视为存活对象,未被标记的对象就是垃圾对象,可以被安全回收。 追踪式垃圾回收算法可以有效解决引用计数算法无法处理循环引用的问题。它通过一个有向图的方式来表示对象之间的引用关系,只要被根节点可达,即使形成环路也不会导致内存泄漏。
常见追踪回收算法
- 标记-清除算法:包括标记和清除两个阶段。标记阶段从根节点遍历标记所有可达对象,清除阶段回收未被标记的对象。
- 标记-整理算法:标记-整理算法的标记阶段和标记-清除算法一样,但后续步骤不是直接清除对象,而是将所有存活对象移向一端,然后直接清理掉端界以外的内存。这种算法避免了内存碎片的产生,但由于需要移动对象,效率比复制算法要低。
- 复制算法:复制算法将可用内存按容量划分为两块相等的空间,每次只使用其中一块。当一块内存用完了,就将还存活的对象复制到另一块上面,然后再把已使用过的内存空间进行一次清理。这种算法的优点是内存空间是连续的,分配内存时也不会产生碎片。缺点是可用内存缩小为原来的一半。
- 三色标记算法:是标记-清除算法的改进版,将对象分为白色(未被访问)、灰色(已访问但引用未扫描)和黑色(已访问且引用已扫描)三种状态,通过状态转换实现并发标记。
核心概念
标记-清扫
Golang 使用的垃圾回收算法属于标记清除(Mark-Sweep)算法,标记清除收集器是跟踪式垃圾回收器,其执行过程可以分成标记(Mark)和清除(Sweep)两个阶段:
- 标记阶段 — 从根对象出发查找并标记堆中所有存活的对象;
- 清除阶段 — 遍历堆中的全部对象,回收未被标记的垃圾对象并释放内存空间;
三色标记
Go 的垃圾回收器 (GC) 使用三色标记和清扫算法,该算法专为并发高效的垃圾回收而设计。该算法将对象分为三种颜色:白色、灰色和黑色,以确定它们的可达性和可回收性。
对象分类
- 白色对象:潜在的可回收对象,其内存可能会被垃圾回收器回收,对象在 GC 阶段的初始状态;
- 黑色对象:活跃的对象,包括所有已探查确认被引用或者根可达的对象,不会被回收;
- 灰色对象:活跃的对象,因为存在指向白色对象的外部指针,垃圾回收器会扫描这些对象的子对象,对象需要进一步被扫描;
标记过程
在垃圾回收器开始工作时,程序中的对象默认都为潜在的可回收对象,即所有对象都为白色。垃圾回收器首先会扫描根对象并标记成灰色,接下来垃圾回收器只会从灰色对象集合中取出对象开始扫描。活跃可达且被扫描过的对象则被标记为黑色。当灰色集合中不存在任何对象时,标记阶段就会结束。标记结束后剩余的白色节点则为需要回收的对象,黑色节点则为活跃的对象。
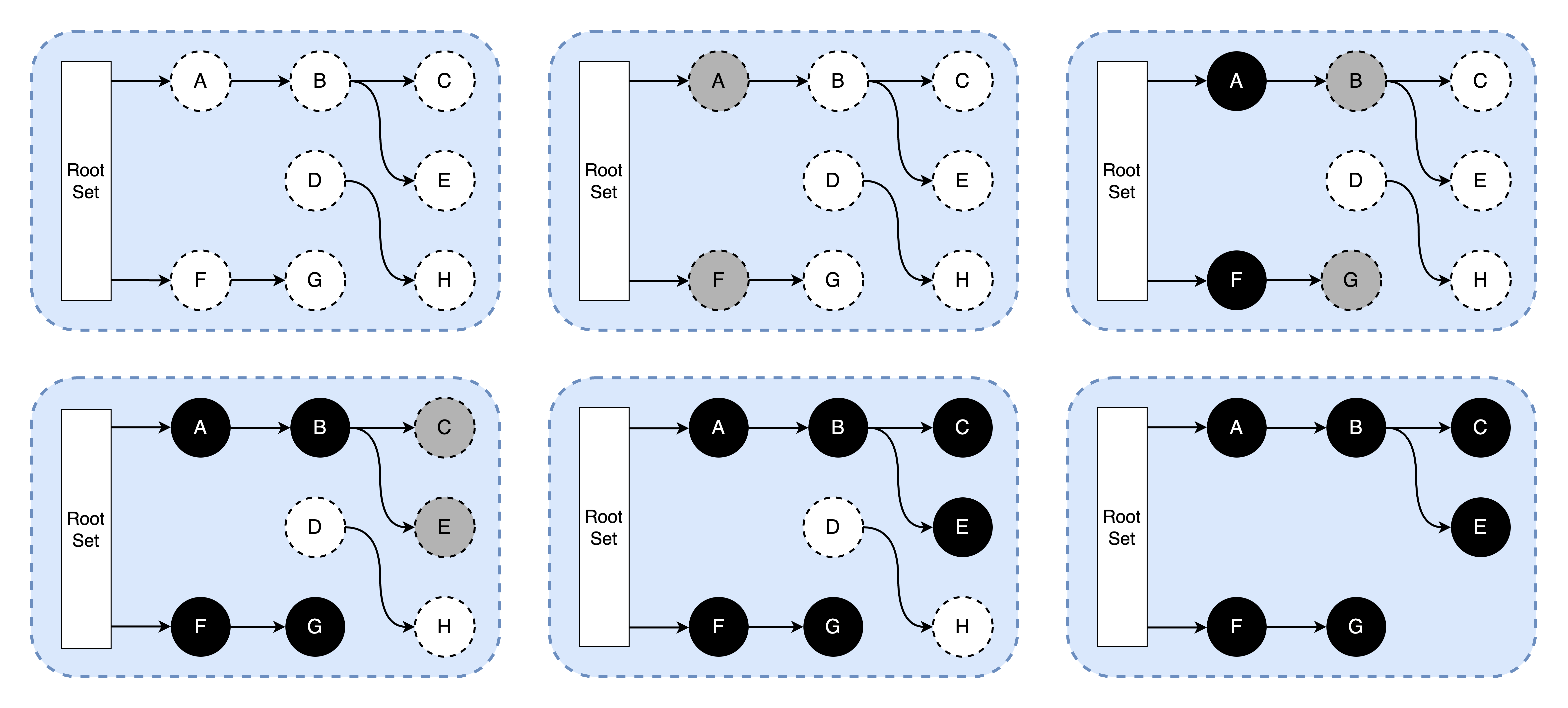
三色标记垃圾回收器的工作原理很简单,我们可以将其归纳成以下几个步骤:
- 起始状态所有对象均为白色对象;
- 遍历根对象集,标记根对象为灰色;
- 从灰色对象的集合中选择一个灰色对象并将其标记成黑色;
- 将黑色对象指向的所有对象都标记成灰色,保证该对象和被该对象引用的对象都不会被回收;
- 重复 3-4 两个步骤直到对象图中不存在灰色对象;
STW(Stop-The-World)
STW指的是在GC的某些关键阶段,需要暂停整个程序的执行(包括所有的goroutine),让CPU全部用于执行GC的工作,这个暂停的过程就是STW。在并发标记和清除阶段,如果不暂停程序执行,用户goroutine持续修改对象引用关系,会导致GC标记工作的正确性受到影响。为了防止这种现象的发生,最简单的方式就是STW,直接禁止掉其他用户程序对对象引用关系的干扰。例如:
- 从 Go 1.5 版本开始,GC 采用的是插入写屏障(Insertion Write Barrier)。这种写屏障只监控了堆上指针数据的变动,但没有监控栈上指针的变动。由于应用 goroutine和 GC 的标记 goroutine 都在并发运行,当栈上的指针指向的对象变更为白色对象时,这个白色对象可能会被错误地认为是垃圾而被回收。
- 为了解决这个问题,Go 1.5 在标记结束阶段需要 Stop-The-World(STW),重新扫描所有 goroutine 的栈,将栈上引用的白色对象标记为存活。这个重新扫描栈的过程就是所谓的 stack-rescaning。stack-rescaning 会导致较长的 STW 暂停时间(为了防止并发修改),影响程序的响应性和延迟性能。
作用
- 标记根对象:在GC的标记阶段开始时,需要通过STW来暂停整个程序的执行,标记出所有根对象(GC Roots),作为后续并发标记的起点。
- 关闭写屏障:在标记阶段结束时,需要通过STW关闭写屏障,为后续的清除阶段做准备。
- 启用写屏障:为下一个GC周期的并发标记做准备,需要通过STW重新启用写屏障。
- 栈重扫描:在Go 1.5及之前的版本中,由于只使用了插入式写屏障,在标记结束后需要再次STW,重新扫描所有goroutine的栈,标记栈上引用的白色对象为存活对象。这个重新扫描栈的过程会导致较长的STW时间。
- 执行清除操作:在一些早期版本中,清除阶段也需要STW来执行。但从Go 1.5开始,清除操作已经并发化,不再需要STW。
写屏障
在Golang的垃圾回收(GC)过程中,写屏障(Write Barrier)是一个关键机制,用于确保在并发标记阶段的正确性和效率。写屏障是一段在指针修改操作之前插入的代码片段。它的主要目的是在垃圾回收的标记阶段,确保所有的指针修改操作都能被正确追踪,从而维护三色标记算法的正确性。
强弱三色不变性
- 强三色不变性:强三色不变性指的是在垃圾回收的标记阶段,不存在黑色对象直接指向白色对象的情况。这里的黑色对象代表已经被扫描过的对象,白色对象代表尚未被扫描的对象。强三色不变性隐含了一层意思:如果该对象是活跃对象,那么必然存在从灰色对象到该对象的路径。这种不变性保证了一旦对象被标记为黑色,它就不会再引用任何未被标记的白色对象,从而避免了在并发标记过程中因程序修改对象引用而导致的活跃对象被错误回收的风险。
- 弱三色不变性:弱三色不变性允许黑色对象直接指向白色对象,但只要存在未访问的能够到达白色对象的路径,就可以将黑色对象指向白色对象。这意味着,即使黑色对象引用了白色对象,只要从灰色对象出发,总存在一条没有访问过的路径到达白色对象,白色对象最终不会被遗漏。弱三色不变性的好处在于它提供了更大的灵活性,允许在垃圾回收的标记阶段进行一定程度的对象引用修改,而不会破坏垃圾回收器的正确性。
只有满足其中一种三色不变性,才能保证 GC 过程中对象不会被错误地回收。为了维护这两种三色不变性,垃圾回收器采用了屏障技术,特别是写屏障。写屏障是一种同步机制,使赋值器在进行指针写操作时,能够同时维护三色标记结果,进而不会破坏弱三色不变性。写屏障通过扩大波面(将白色对象作色成灰色)、推进波面(扫描对象并将其着色为黑色)和后退波面(将黑色对象回退到灰色)等操作来应对指针的插入和删除,从而保证垃圾回收过程的正确性。
插入写屏障
Dijkstra 在 1978 年提出了插入写屏障,通过如下所示的写屏障,用户程序和垃圾回收器可以在交替工作的情况下保证程序执行的正确性:
// 灰色赋值器 Dijkstra 插入屏障
func DijkstraWritePointer(slot *unsafe.Pointer, ptr unsafe.Pointer) {
shade(ptr)
*slot = ptr
}
为了防止黑色对象指向白色对象,应该假设 *slot 可能会变为黑色,为了确保 ptr 不会在被赋值到 *slot 前变为白色,shade(ptr) 会先将指针 ptr 标记为灰色。
插入式的 Dijkstra 写屏障虽然实现非常简单并且也能保证强三色不变性,但是它也有明显的缺点。因为栈上的对象在垃圾回收中也会被认为是根对象,所以为了保证内存的安全,Dijkstra 必须为栈上的对象增加写屏障或者在标记阶段完成重新对栈上的对象进行扫描,这两种方法各有各的缺点,前者会大幅度增加写入指针的额外开销,后者重新扫描栈对象时需要暂停程序,垃圾回收算法的设计者需要在这两者之间做出权衡。
删除写屏障
Yuasa 在 1990 年的论文 Real-time garbage collection on general-purpose machines 中提出了删除写屏障,因为一旦该写屏障开始工作,它会保证开启写屏障时堆上所有对象的可达,所以也被称作快照垃圾回收(Snapshot GC)(10):
This guarantees that no objects will become unreachable to the garbage collector traversal all objects which are live at the beginning of garbage collection will be reached even if the pointers to them are overwritten.
该算法会使用如下所示的写屏障保证增量或者并发执行垃圾回收时程序的正确性:
// 黑色赋值器 Yuasa 屏障
func YuasaWritePointer(slot *unsafe.Pointer, ptr unsafe.Pointer) {
shade(*slot)
*slot = ptr
}
上述代码会在老对象的引用被删除时,将白色的老对象标记为灰色对象,这样删除写屏障就可以保证弱三色不变性,老对象引用的下游对象一定可以被灰色对象引用。
迭代过程
Go 语言的垃圾回收器从诞生的第一天起就一直在演进,除了少数几个版本没有大更新之外,几乎每次发布的小版本都会提升垃圾回收的性能,而与性能一同提升的还有垃圾回收器代码的复杂度,本节将从 Go 语言 v1.0 版本开始分析垃圾回收器的演进过程。
- go1.0:完全串行的标记和清除过程,需要暂停整个程序;
- go1.1:在多核主机并行执行垃圾回收的标记和清除阶段,提高回收效率和准确性;
- go1.3:运行时基于只有指针类型的值包含指针的假设增加了对栈内存的精确扫描支持,实现了真正精确的垃圾回收;将
unsafe.Pointer类型转换成整数类型的值认定为非法操作,可能会造成悬挂指针等严重问题; - go1.4:使用 Go 重写部分垃圾回收逻辑,进一步优化性能,引入写屏障,为后续的并发标记垃圾回收器做准备。
- go1.5:实现了基于三色标记清扫的并发垃圾回收器;
- 大幅度降低垃圾回收的延迟从几百 ms 降低至 10ms 以下;
- 计算垃圾回收启动的合适时间并通过并发加速垃圾回收的过程;
- go1.6:实现了去中心化的垃圾回收协调器;
- 基于显式的状态机使得任意 Goroutine 都能触发垃圾回收的状态迁移;
- 使用密集的位图替代空闲链表表示的堆内存,降低清除阶段的 CPU 占用;
- go1.7:通过并行栈收缩将垃圾回收的时间缩短至 2ms 以内;
- go1.8:引入了混合写屏障(Hybrid Write Barrier),结合了插入屏障和删除屏障的优点,避免了对栈重新扫描的需求,极大减少了STW时间;
- go1.9:彻底移除暂停程序的重新扫描栈的过程;
- go1.10:更新了垃圾回收调频器(Pacer)的实现,分离软硬堆大小的目标;
- go1.12:使用新的标记终止算法简化垃圾回收器的几个阶段;
- go1.13:通过新的 Scavenger 解决瞬时内存占用过高的应用程序向操作系统归还内存的问题;
实现原理
GC 状态
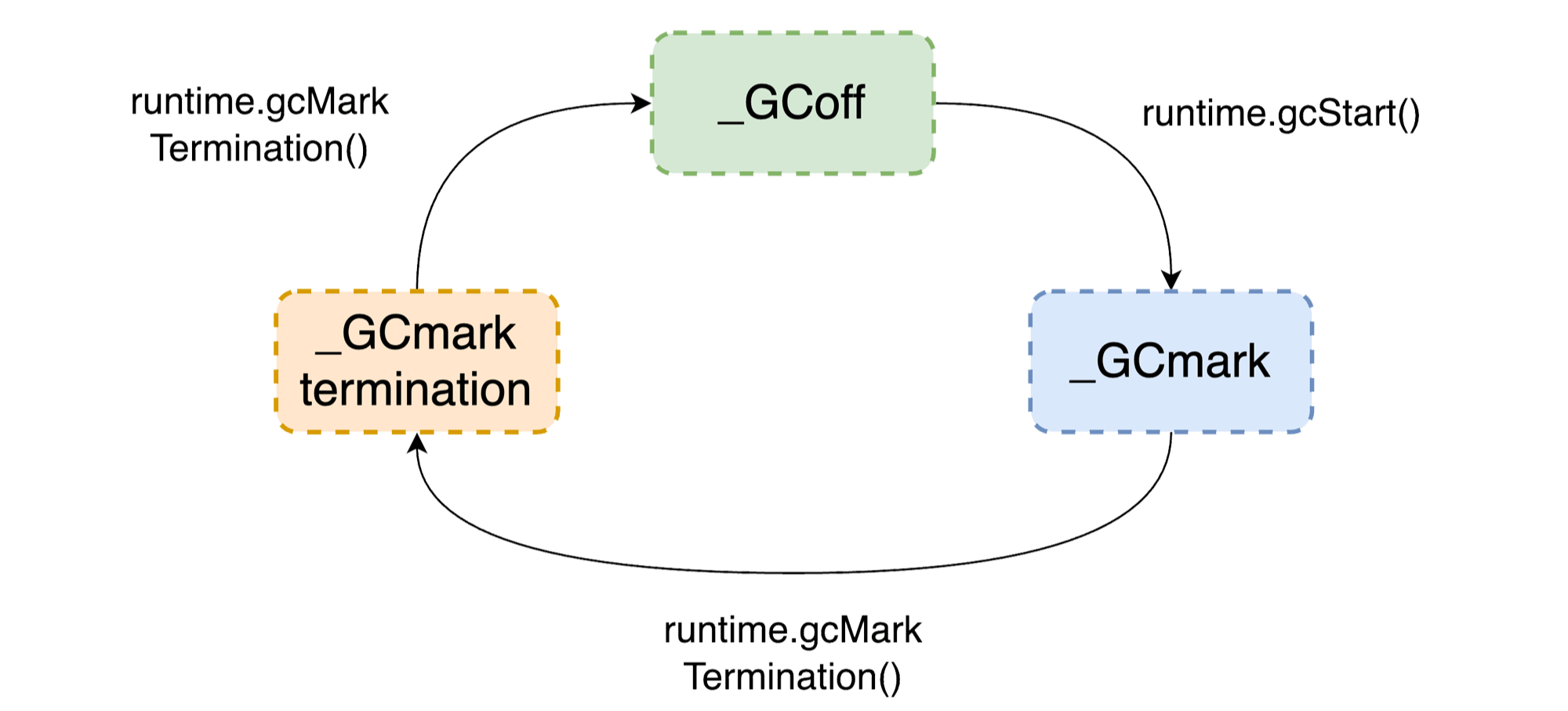
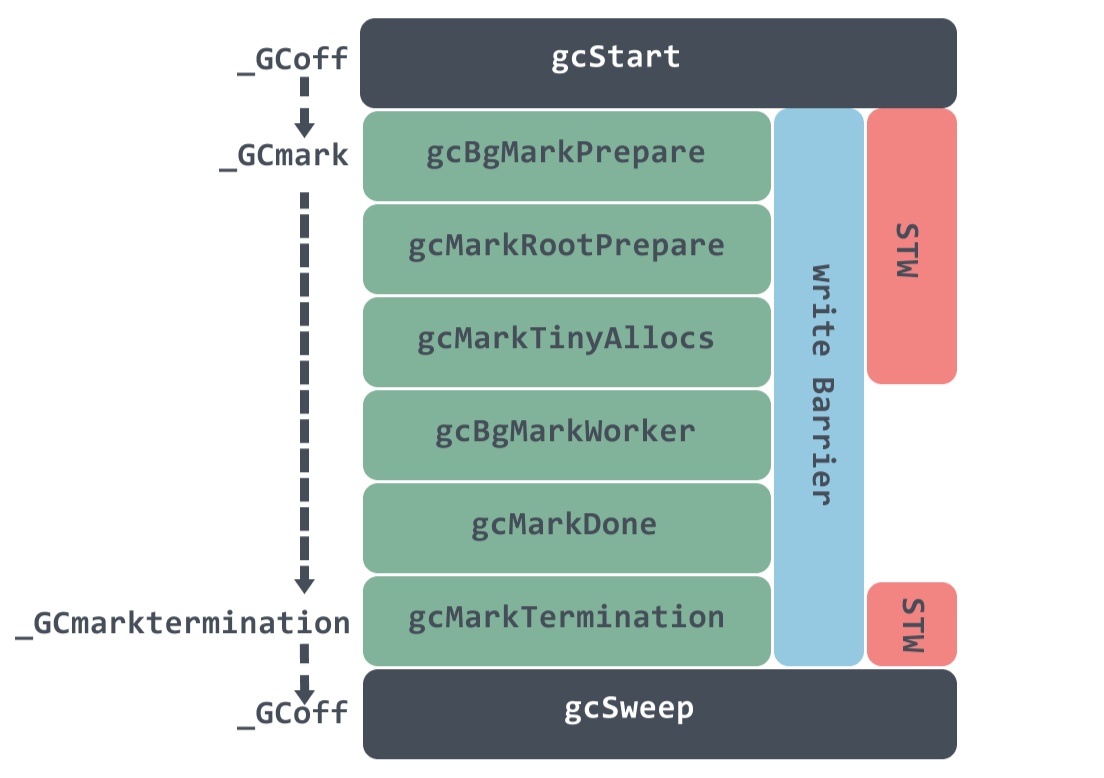
Go语言的垃圾回收器(GC)在工作过程中主要有以下几个状态:
- 标记阶段(_GCmark):
这个阶段会短暂停止整个程序(Stop-the-World, STW),开启写屏障,标记从根对象(如全局变量、栈上变量等)直接可达的对象。随后 GC 协程和应用程序协程并发运行,从标记的根对象开始,递归标记所有可达的对象。 - 清除阶段(_GCmarktermination)
在标记完所有活跃对象后,GC会进入清除阶段,回收未被标记的对象所占用的内存。GC和应用程序线程并发运行,GC清除那些在标记阶段未被标记为"活跃"的对象 - 关闭状态(_GCoff)
当标记和清除阶段都完成后,GC会进入关闭状态,写屏障也会被关闭,这时不会有任何GC相关的工作在执行。
关键变量
在垃圾回收中有一些比较重要的全局变量,在分析其过程之前,我们会先逐一介绍这些重要的变量,这些变量在垃圾回收的各个阶段中会反复出现,所以理解他们的功能是非常重要的,我们先介绍一些比较简单的变量:
runtime.gcphase是垃圾回收器当前处于的阶段,可能处于_GCoff、_GCmark和_GCmarktermination,Goroutine 在读取或者修改该阶段时需要保证原子性;// src/runtime/mgc.go // Garbage collector phase. // Indicates to write barrier and synchronization task to perform. var gcphase uint32 // gcphase 主要通过以下函数修改 //go:nosplit func setGCPhase(x uint32) { atomic.Store(&gcphase, x) writeBarrier.enabled = gcphase == _GCmark || gcphase == _GCmarktermination }runtime.gcBlackenEnabled是一个布尔值,当垃圾回收处于标记阶段时,该变量会被置为 1,随后辅助垃圾回收的用户程序协程和后台标记协程可以将对象涂黑;// src/runtime/mgc.go // gcBlackenEnabled is 1 if mutator assists and background mark // workers are allowed to blacken objects. This must only be set when // gcphase == _GCmark. var gcBlackenEnabled uint32runtime.gcController实现了垃圾回收的调步算法,它能够决定触发并行垃圾回收的时间和待处理的工作;// src/runtime/mgcpacer.go // gcController implements the GC pacing controller that determines // when to trigger concurrent garbage collection and how much marking // work to do in mutator assists and background marking. // // It calculates the ratio between the allocation rate (in terms of CPU // time) and the GC scan throughput to determine the heap size at which to // trigger a GC cycle such that no GC assists are required to finish on time. // This algorithm thus optimizes GC CPU utilization to the dedicated background // mark utilization of 25% of GOMAXPROCS by minimizing GC assists. // GOMAXPROCS. The high-level design of this algorithm is documented // at https://github.com/golang/proposal/blob/master/design/44167-gc-pacer-redesign.md. // See https://golang.org/s/go15gcpacing for additional historical context. var gcController gcControllerStategcPercent是触发垃圾回收的内存增长百分比,默认情况下为 100,即堆内存相比上次垃圾回收增长 100% 时应该触发 GC,并行的垃圾回收器会在到达该目标前完成垃圾回收;memoryLimitgo1.19 软性内存限制特性,为避免因内存耗尽导致程序被终止,将更积极地返还内存给操作系统。同时该数值可以通过GOMEMLIMIT调整,通过适当配置可以调整 GC 的频率。heapMinimum设置最低触发 GC 的堆内存阈值。- ......
- 总体来说,
runtime.gcController中包含大量字段作用于 GC 调步算法的参数,用于精细化调控 GC 的触发时机,回收目标等
runtime.writeBarrier是一个包含写屏障状态的结构体,其中的enabled字段表示写屏障的开启与关闭;// src/runtime/mgc.go // The compiler knows about this variable. // If you change it, you must change builtin/runtime.go, too. // If you change the first four bytes, you must also change the write // barrier insertion code. var writeBarrier struct { enabled bool // compiler emits a check of this before calling write barrier pad [3]byte // compiler uses 32-bit load for "enabled" field alignme uint64 // guarantee alignment so that compiler can use a 32 or 64-bit load }runtime.worldsema是全局的信号量,获取该信号量的线程有权利暂停当前应用程序;// src/runtime/proc.go // Holding worldsema grants an M the right to try to stop the world. var worldsema uint32 = 1runtime.work该结构体中包含大量垃圾回收的相关字段,例如:表示完成的垃圾回收循环的次数、当前循环时间和 CPU 的利用率、垃圾回收的模式、协助队列等等// src/runtime/mgc.go var work workType type workType struct { full lfstack // lock-free list of full blocks workbuf _ cpu.CacheLinePad // prevents false-sharing between full and empty empty lfstack // lock-free list of empty blocks workbuf _ cpu.CacheLinePad // prevents false-sharing between empty and nproc/nwait wbufSpans struct { lock mutex // free is a list of spans dedicated to workbufs, but // that don't currently contain any workbufs. free mSpanList // busy is a list of all spans containing workbufs on // one of the workbuf lists. busy mSpanList } ... // mode is the concurrency mode of the current GC cycle. mode gcMode // userForced indicates the current GC cycle was forced by an // explicit user call. userForced bool // initialHeapLive is the value of gcController.heapLive at the // beginning of this GC cycle. initialHeapLive uint64 // assistQueue is a queue of assists that are blocked because // there was neither enough credit to steal or enough work to // do. assistQueue struct { lock mutex q gQueue } ... // cycles is the number of completed GC cycles, where a GC // cycle is sweep termination, mark, mark termination, and // sweep. This differs from memstats.numgc, which is // incremented at mark termination. cycles atomic.Uint32 ... }
触发类型
runtime 包中有专门的常量用于标记 GC 的触发类型:
// src/runtime/mgc.go
// A gcTrigger is a predicate for starting a GC cycle. Specifically,
// it is an exit condition for the _GCoff phase.
type gcTrigger struct {
kind gcTriggerKind
now int64 // gcTriggerTime: current time
n uint32 // gcTriggerCycle: cycle number to start
}
type gcTriggerKind int
const (
// gcTriggerHeap 表示当堆大小达到调步控制器
// 计算的触发堆大小时而启动的 GC 循环。
gcTriggerHeap gcTriggerKind = iota
// gcTriggerTime 表示当距离上一次 GC 循环超过
// forcegcperiod(2mins) 所规定的时长,而启动的 GC 循环。
gcTriggerTime
// gcTriggerCycle 表示如果当前还没有开始第 N 轮垃圾回收,
// 则启动GC,主要是通过 runtime.GC() 手动触发
gcTriggerCycle
)
// src/runtime/proc.go
// forcegcperiod is the maximum time in nanoseconds between garbage
// collections. If we go this long without a garbage collection, one
// is forced to run.
//
// This is a variable for testing purposes. It normally doesn't change.
var forcegcperiod int64 = 2 * 60 * 1e9
触发流程
运行时会通过 runtime.gcTrigger.test 方法决定是否需要触发垃圾回收,当满足触发垃圾回收的基本条件时,该方法会根据三种不同方式触发进行不同的检查:
// test reports whether the trigger condition is satisfied, meaning
// that the exit condition for the _GCoff phase has been met. The exit
// condition should be tested when allocating.
func (t gcTrigger) test() bool {
// 触发 GC 的基础条件:
// 1. 允许垃圾回收
// 2. 程序没有崩溃
// 3. 没有处于垃圾回收循环
if !memstats.enablegc || panicking.Load() != 0 || gcphase != _GCoff {
return false
}
// 根据触发类型进行检查
switch t.kind {
case gcTriggerHeap:
trigger, _ := gcController.trigger()
return gcController.heapLive.Load() >= trigger
case gcTriggerTime:
if gcController.gcPercent.Load() < 0 {
return false
}
lastgc := int64(atomic.Load64(&memstats.last_gc_nanotime))
return lastgc != 0 && t.now-lastgc > forcegcperiod
case gcTriggerCycle:
// t.n > work.cycles, but accounting for wraparound.
return int32(t.n-work.cycles.Load()) > 0
}
return true
}
gcTriggerHeap:堆内存的分配达到控制器计算的触发堆大小;gcTriggerTime:如果一定时间内没有触发,就会触发新的循环,触发间隔由runtime.forcegcperiod变量控制,默认为 2 分钟;gcTriggerCycle:如果当前没有开启垃圾回收,则触发新的循环;
根据 gcTrigger.test() 的调用可以跟踪到下列 GC 触发流程:
runtime.sysmon和runtime.forcegchelper:后台运行定时检查和垃圾回收;runtime.GC:用户程序手动触发垃圾回收;runtime.mallocgc:申请内存时根据堆大小触发垃圾回收;
堆内存分配
调用 runtime.mallocgc 申请内存空间的时候,会根据运行时情况修改 shouldhelpgc 变量,并据此决定是否要触发 GC:
// Allocate an object of size bytes.
// Small objects are allocated from the per-P cache's free lists.
// Large objects (> 32 kB) are allocated straight from the heap.
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
if gcphase == _GCmarktermination {
throw("mallocgc called with gcphase == _GCmarktermination")
}
...
shouldhelpgc := false
if size <= maxSmallSize-mallocHeaderSize {
if noscan && size < maxTinySize {
...
v := nextFreeFast(span)
if v == 0 {
// 微对象内存申请
v, span, shouldhelpgc = c.nextFree(tinySpanClass)
}
...
} else {
...
// 小对象内存申请
v := nextFreeFast(span)
if v == 0 {
v, span, shouldhelpgc = c.nextFree(spc)
}
} else {
// 大对象内存申请
shouldhelpgc = true
...
}
...
if shouldhelpgc {
if t := (gcTrigger{kind: gcTriggerHeap}); t.test() {
gcStart(t)
}
}
...
}
运行时会将堆上的对象按大小分成微对象、小对象和大对象三类,这三类对象的内存分配都可能会触发新的垃圾回收循环:
- 创建微对象和小对象需要调用
runtime.mcache.nextFree从中心缓存或者页堆中获取新的管理单元,如果当前线程的内存管理单元中不存在空闲空间时,就可能触发垃圾回收; - 当用户程序申请分配 32KB 以上的大对象时,一定会构建
runtime.gcTrigger尝试触发垃圾回收;
通过堆内存触发垃圾回收需要比较 runtime.mstats 中的两个字段 — 表示垃圾回收中存活对象字节数的 heap_live 和表示触发标记的堆内存大小的 gc_trigger;当内存中存活的对象字节数大于触发垃圾回收的堆大小时,新一轮的垃圾回收就会开始。在这里,我们将分别介绍这两个值的计算过程:
heap_live:为了减少锁竞争,运行时只会在中心缓存分配或者释放内存管理单元以及在堆上分配大对象时才会更新;gc_trigger:在标记终止阶段调用runtime.gcSetTriggerRatio更新触发下一次垃圾回收的堆大小;
runtime.gcController 会在每个循环结束后计算触发比例并通过 runtime.gcSetTriggerRatio 设置 gc_trigger,它能够决定触发垃圾回收的时间以及用户程序和后台处理的标记任务的多少,利用反馈控制的算法根据堆的增长情况和垃圾回收 CPU 利用率确定触发垃圾回收的时机。
后台触发
运行时会在应用程序启动时通过 init() 函数 go 一个用于强制触发垃圾回收的 Goroutine,该 Goroutine 将循环调用 runtime.gcStart 尝试启动新一轮的垃圾回收:
// src/runtime/proc.go
// start forcegc helper goroutine
func init() {
go forcegchelper()
}
func forcegchelper() {
forcegc.g = getg()
lockInit(&forcegc.lock, lockRankForcegc)
for {
lock(&forcegc.lock)
if forcegc.idle.Load() {
throw("forcegc: phase error")
}
forcegc.idle.Store(true)
goparkunlock(&forcegc.lock, waitReasonForceGCIdle, traceBlockSystemGoroutine, 1)
// this goroutine is explicitly resumed by sysmon
if debug.gctrace > 0 {
println("GC forced")
}
// Time-triggered, fully concurrent.
gcStart(gcTrigger{kind: gcTriggerTime, now: nanotime()})
}
}
为了避免频繁循环对计算资源的占用,该 Goroutine 会在循环中调用 runtime.goparkunlock 主动进入休眠等待唤醒,在大多数时间都是陷入休眠的,但是它会被系统监控器 runtime.sysmon 在满足垃圾回收条件时唤醒:
// src/runtime/proc.go
// Always runs without a P, so write barriers are not allowed.
//
//go:nowritebarrierrec
func sysmon() {
...
for {
...
// check if we need to force a GC
if t := (gcTrigger{kind: gcTriggerTime, now: now}); t.test() && forcegc.idle.Load() {
lock(&forcegc.lock)
forcegc.idle.Store(false)
var list gList
list.push(forcegc.g)
injectglist(&list)
unlock(&forcegc.lock)
}
...
}
}
sysmon 会在 main goroutine 启动的时候创建专用的 m 进行调度执行。
// src/runtime/proc.go
// The main goroutine.
func main() {
...
if GOARCH != "wasm" { // no threads on wasm yet, so no sysmon
systemstack(func() {
newm(sysmon, nil, -1)
})
}
...
}
人工触发
用户可通过 runtime.GC 函数在运行期间主动调用执行 GC 循环。该方法在调用时会阻塞调用方直到当前垃圾回收循环完成,在垃圾回收期间也可能会通过 STW 暂停整个程序。
// src/runtime/mgc.go
// GC 运行垃圾回收并阻塞调用者,直到垃圾回收完成。它也可能阻塞整个程序。
func GC() {
// 我们认为一个周期包括:扫描终止、标记、标记终止和扫描。
// 在一个完整的周期(从开始到结束)完成之前,该函数不应返回。
// 因此,我们总是希望结束当前周期并开始一个新的周期。也就是说:
//
// 1. 如果处于第 N 轮循环的清扫结束、标记或标记结束阶段,
// 则等待第 N 轮循环完成标记后,进入清扫阶段。
//
// 2. 进入第 N 轮循环的清扫阶段,协助清扫。
//
// 至此之后我们就可以完整执行一次循环,即 N+1 轮循环
//
// 3. 触发第 N+1 轮循环
//
// 4. 等待 N+1 轮循环标记结束
//
// 5. 协助 N+1 轮的清扫工作
//
// This all has to be written to deal with the fact that the
// GC may move ahead on its own. For example, when we block
// until mark termination N, we may wake up in cycle N+2.
// 等待当前循环标记等阶段结束
n := work.cycles.Load()
gcWaitOnMark(n)
// 触发 N+1 轮循环
gcStart(gcTrigger{kind: gcTriggerCycle, n: n + 1})
// 等待 N+1 轮循环标记完成
gcWaitOnMark(n + 1)
// 函数返回前完成 N+1 轮的清理工作,这样设计的目的是因为 runtime.GC()
// 常用于测试或测评,它能让系统处于一个相对稳定且堵路的状态
for work.cycles.Load() == n+1 && sweepone() != ^uintptr(0) {
Gosched()
}
// Callers may assume that the heap profile reflects the
// just-completed cycle when this returns (historically this
// happened because this was a STW GC), but right now the
// profile still reflects mark termination N, not N+1.
//
// As soon as all of the sweep frees from cycle N+1 are done,
// we can go ahead and publish the heap profile.
//
// First, wait for sweeping to finish. (We know there are no
// more spans on the sweep queue, but we may be concurrently
// sweeping spans, so we have to wait.)
for work.cycles.Load() == n+1 && !isSweepDone() {
Gosched()
}
// Now we're really done with sweeping, so we can publish the
// stable heap profile. Only do this if we haven't already hit
// another mark termination.
mp := acquirem()
cycle := work.cycles.Load()
if cycle == n+1 || (gcphase == _GCmark && cycle == n+2) {
mProf_PostSweep()
}
releasem(mp)
}
- 在正式开始垃圾回收前,运行时需要通过
runtime.gcWaitOnMark等待上一个循环的标记终止、标记和清除终止阶段完成; - 调用
runtime.gcStart触发新一轮的垃圾回收并通过runtime.gcWaitOnMark等待该轮垃圾回收的标记终止阶段正常结束; - 持续调用
runtime.sweepone清理全部待处理的内存管理单元并等待所有的清理工作完成,等待期间会调用runtime.Gosched让出处理器; - 完成本轮垃圾回收的清理工作后,通过
runtime.mProf_PostSweep将该阶段的堆内存状态快照发布出来,我们可以获取这时的内存状态;
回收流程
启动
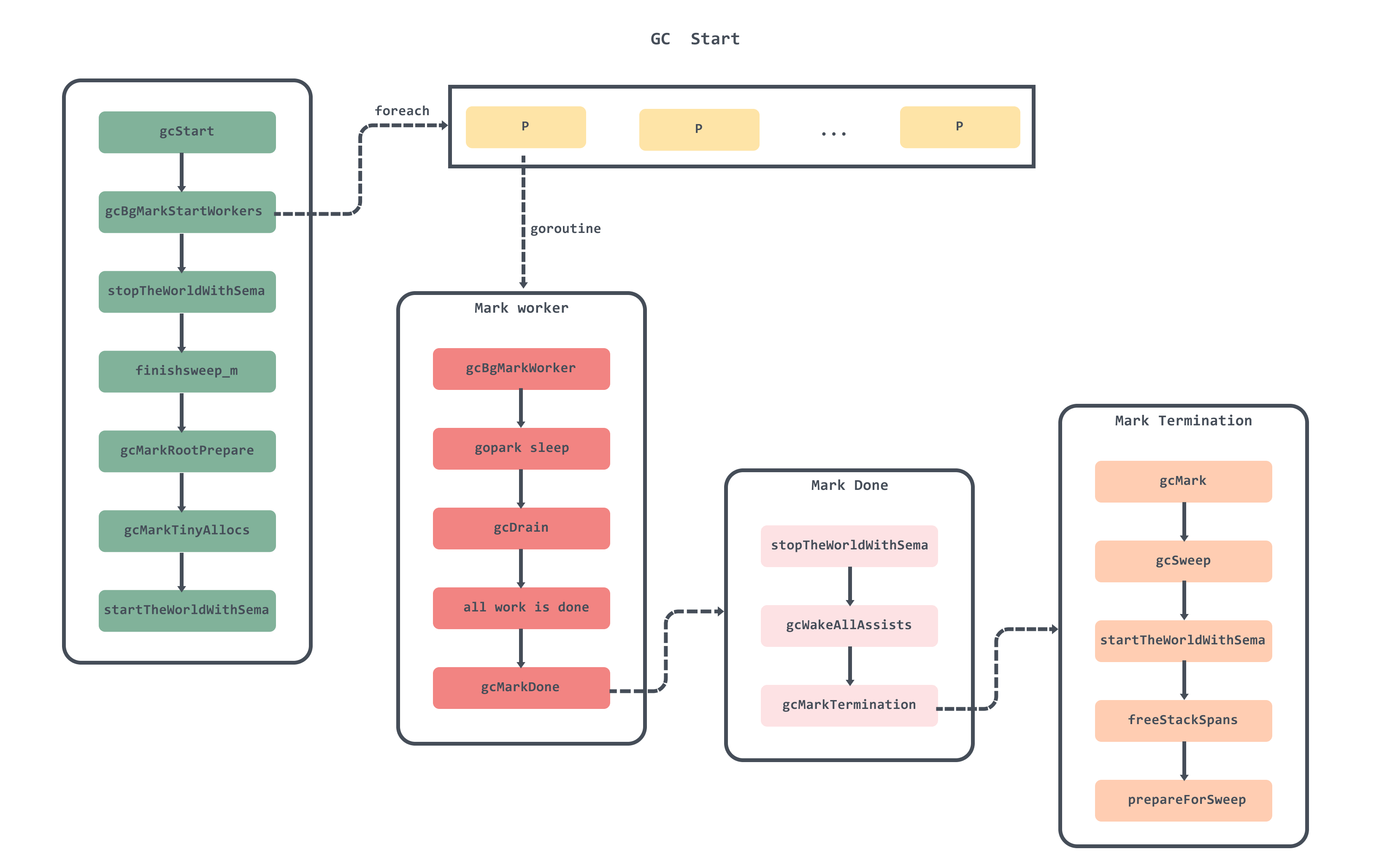
垃圾回收在启动过程一定会调用 runtime.gcStart,该函数主要流程如下:
- 函数首先获取当前的 M(操作系统线程)并检查当前的 G(协程)是否在系统栈(
g0)上运行,当前 M 是否持有多个锁,或者是否被抢占。如果这些条件中的任何一个为真,它会释放 M 并中止垃圾回收,以避免在 GC 期间可能发生的死锁或不安全状态。func gcStart(trigger gcTrigger) { // Since this is called from malloc and malloc is called in // the guts of a number of libraries that might be holding // locks, don't attempt to start GC in non-preemptible or // potentially unstable situations. mp := acquirem() if gp := getg(); gp == mp.g0 || mp.locks > 1 || mp.preemptoff != "" { releasem(mp) return } releasem(mp) mp = nil ... } - 检查是否满足 GC 触发条件,兜底清理已标记但未被清理的对象(一般后台清理不会出现该情况),但在强制触发时,该机制可以协助清理对象。
func gcStart(trigger gcTrigger) { ... for trigger.test() && sweepone() != ^uintptr(0) { } ... } - 获取 GC 启动的信号量,再次检查是否符合 GC 条件。
func gcStart(trigger gcTrigger) { ... // Perform GC initialization and the sweep termination // transition. semacquire(&work.startSema) // Re-check transition condition under transition lock. if !trigger.test() { semrelease(&work.startSema) return } ... } - 根据参数选择 GC 工作模式,获取 GC 信号量和全局的信号量。
func gcStart(trigger gcTrigger) { ... mode := gcBackgroundMode if debug.gcstoptheworld == 1 { mode = gcForceMode } else if debug.gcstoptheworld == 2 { mode = gcForceBlockMode } // Ok, we're doing it! Stop everybody else semacquire(&gcsema) semacquire(&worldsema) // For stats, check if this GC was forced by the user. // Update it under gcsema to avoid gctrace getting wrong values. work.userForced = trigger.kind == gcTriggerCycle ... } - 在检查所有 P 不包含未清理的 mcache 后,调用
gcBgMarkStartWorkers启动后台标记 Worker。func gcStart(trigger gcTrigger) { ... // Check that all Ps have finished deferred mcache flushes. for _, p := range allp { if fg := p.mcache.flushGen.Load(); fg != mheap_.sweepgen { println("runtime: p", p.id, "flushGen", fg, "!= sweepgen", mheap_.sweepgen) throw("p mcache not flushed") } } gcBgMarkStartWorkers() ... } - 修改全局变量
work和gcController中的必要参数。func gcStart(trigger gcTrigger) { ... work.stwprocs, work.maxprocs = gomaxprocs, gomaxprocs if work.stwprocs > ncpu { // This is used to compute CPU time of the STW phases, // so it can't be more than ncpu, even if GOMAXPROCS is. work.stwprocs = ncpu } work.heap0 = gcController.heapLive.Load() work.pauseNS = 0 work.mode = mode now := nanotime() work.tSweepTerm = now ... work.cycles.Add(1) // Assists and workers can start the moment we start // the world. gcController.startCycle(now, int(gomaxprocs), trigger) // Notify the CPU limiter that assists may begin. gcCPULimiter.startGCTransition(true, now) } - 调用
stopTheWorldWithSema暂停程序func gcStart(trigger gcTrigger) { ... var stw worldStop systemstack(func() { stw = stopTheWorldWithSema(stwGCSweepTerm) }) ... } - 调用
setGCPhase设置全局变量中的GC状态为_GCmark,然后启用写屏障;func gcStart(trigger gcTrigger) { ... // 进入并发标记阶段并开启写屏障 // // 由于 STW, 修改 gcphase 会同时修改 writeBarrier.enable // 同时所有 P 会监听 writeBarrier 变量开启写屏障 // 一旦重启执行,写屏障将无缝开启 setGCPhase(_GCmark) ... } - 调用
gcBgMarkPrepare初始化后台扫描需要的状态;func gcStart(trigger gcTrigger) { ... gcBgMarkPrepare() // Must happen before assists are enabled. ... } - 调用
gcMarkRootPrepare将扫描栈上、全局变量等根对象并将它们加入队列;func gcStart(trigger gcTrigger) { ... gcMarkRootPrepare() ... } - 调用
gcMarkTinyAllocs标记所有微对象内存块;func gcStart(trigger gcTrigger) { ... gcMarkTinyAllocs() ... } - 设置
gcBlackenEnabled,用户协程和标记协程可以将对象变黑;func gcStart(trigger gcTrigger) { ... atomic.Store(&gcBlackenEnabled, 1) ... } - 记录完标记开始的时间后,调用
startTheWorldWithSema启动程序,后台任务也会开始标记堆中的对象,同时写入部分 GC 任务指标数据;func gcStart(trigger gcTrigger) { ... // Concurrent mark. systemstack(func() { now = startTheWorldWithSema(0, stw) work.pauseNS += now - stw.start work.tMark = now sweepTermCpu := int64(work.stwprocs) * (work.tMark - work.tSweepTerm) work.cpuStats.gcPauseTime += sweepTermCpu work.cpuStats.gcTotalTime += sweepTermCpu // Release the CPU limiter. gcCPULimiter.finishGCTransition(now) }) ... } - 释放获取到的信号量。
func gcStart(trigger gcTrigger) { ... semrelease(&worldsema) releasem(mp) // Make sure we block instead of returning to user code // in STW mode. if mode != gcBackgroundMode { Gosched() } semrelease(&work.startSema) }
后台标记
启动标记协程
启动阶段中会调用 gcBgMarkStartWorkers 为每一个 P 都创建一个执行函数 gcBgMarkWorker 的 goroutine,在调用 startTheWorldWithSema 后会被 gcController 调度。
// gcBgMarkStartWorkers prepares background mark worker goroutines. These
// goroutines will not run until the mark phase, but they must be started while
// the work is not stopped and from a regular G stack. The caller must hold
// worldsema.
func gcBgMarkStartWorkers() {
// Background marking is performed by per-P G's. Ensure that each P has
// a background GC G.
//
// Worker Gs don't exit if gomaxprocs is reduced. If it is raised
// again, we can reuse the old workers; no need to create new workers.
for gcBgMarkWorkerCount < gomaxprocs {
go gcBgMarkWorker()
notetsleepg(&work.bgMarkReady, -1)
noteclear(&work.bgMarkReady)
// The worker is now guaranteed to be added to the pool before
// its P's next findRunnableGCWorker.
gcBgMarkWorkerCount++
}
}
标记协程工作类型
用于并发扫描对象的工作协程 Goroutine 总共有三种不同的模式 runtime.gcMarkWorkerMode,这三种不同模式的 Goroutine 在标记对象时使用完全不同的策略,垃圾回收控制器会按照需要执行不同类型的工作协程:
gcMarkWorkerDedicatedMode:特定 P 专门负责标记对象,不会被调度器抢占;gcMarkWorkerFractionalMode:当垃圾回收的后台 CPU 使用率达不到预期时(默认为 25%),启动该类型的工作协程帮助垃圾回收达到利用率的目标,因为它只占用同一个 CPU 的部分资源,所以可以被调度;gcMarkWorkerIdleMode:当 P 没有可以执行的 Goroutine 时,它会运行垃圾回收的标记任务直到被抢占;
在调用 gcController.startCycle 的过程中,gcController 会根据 P 的个数和垃圾回收的 CPU 利用率计算出 dedicatedMarkWorkersNeeded 和 fractionalUtilizationGoal 的值用于决定不同工作模式下的协程数量。
// startCycle resets the GC controller's state and computes estimates
// for a new GC cycle. The caller must hold worldsema and the world
// must be stopped.
func (c *gcControllerState) startCycle(markStartTime int64, procs int, trigger gcTrigger) {
...
// 计算后台标记 CPU 利用率目标。一般来说,计算结果可能并不精确。
// 我们会四舍五入专用 Worker 的数量,使利用率最接近 25%。
// 对于较小的 GOMAXPROCS,就会带来较大的误差,
// 因此我们会在这种情况下增加 Fractional Worker。
totalUtilizationGoal := float64(procs) * gcBackgroundUtilization
dedicatedMarkWorkersNeeded := int64(totalUtilizationGoal + 0.5)
utilError := float64(dedicatedMarkWorkersNeeded)/totalUtilizationGoal - 1
const maxUtilError = 0.3
if utilError < -maxUtilError || utilError > maxUtilError {
// 四舍五入后,如果和预期目标相差 30%。
// 例如当 gcBackgroundUtilization 为 25% 时,
// 且 GOMAXPROCS<=3 或 GOMAXPROCS=6 会出现这种情况。
// 启用 Fractional Worker 来补偿。
if float64(dedicatedMarkWorkersNeeded) > totalUtilizationGoal {
// Too many dedicated workers.
dedicatedMarkWorkersNeeded--
}
c.fractionalUtilizationGoal = (totalUtilizationGoal - float64(dedicatedMarkWorkersNeeded)) / float64(procs)
} else {
c.fractionalUtilizationGoal = 0
}
// 在 STW 模式下,只创建专用 worker
if debug.gcstoptheworld > 0 {
dedicatedMarkWorkersNeeded = int64(procs)
c.fractionalUtilizationGoal = 0
}
...
}
gcController 在调度协程的过程中会设置 P 的 gcMarkWorkerMode
// findRunnableGCWorker returns a background mark worker for pp if it
// should be run. This must only be called when gcBlackenEnabled != 0.
func (c *gcControllerState) findRunnableGCWorker(pp *p, now int64) (*g, int64) {
...
if decIfPositive(&c.dedicatedMarkWorkersNeeded) {
// This P is now dedicated to marking until the end of
// the concurrent mark phase.
pp.gcMarkWorkerMode = gcMarkWorkerDedicatedMode
} else if c.fractionalUtilizationGoal == 0 {
// No need for fractional workers.
gcBgMarkWorkerPool.push(&node.node)
return nil, now
} else {
// Is this P behind on the fractional utilization
// goal?
//
// This should be kept in sync with pollFractionalWorkerExit.
delta := now - c.markStartTime
if delta > 0 && float64(pp.gcFractionalMarkTime)/float64(delta) > c.fractionalUtilizationGoal {
// Nope. No need to run a fractional worker.
gcBgMarkWorkerPool.push(&node.node)
return nil, now
}
// Run a fractional worker.
pp.gcMarkWorkerMode = gcMarkWorkerFractionalMode
}
...
}
除了控制器要求的 Dedicate 和 Fractional 工作协程之外,调度器还会在 findrunnable 中利用空闲的处理器执行垃圾回收的 Idel 类型的工作协程以加速该过程:
// Finds a runnable goroutine to execute.
// Tries to steal from other P's, get g from local or global queue, poll network.
// tryWakeP indicates that the returned goroutine is not normal (GC worker, trace
// reader) so the caller should try to wake a P.
func findRunnable() (gp *g, inheritTime, tryWakeP bool) {
...
top:
...
// Try to schedule a GC worker.
// 优先调度 Dedicate 和 Fractional GC worker
if gcBlackenEnabled != 0 {
gp, tnow := gcController.findRunnableGCWorker(pp, now)
if gp != nil {
return gp, false, true
}
now = tnow
}
...
}
func findRunnable() (gp *g, inheritTime, tryWakeP bool) {
...
top:
...
// We have nothing to do.
//
// If we're in the GC mark phase, can safely scan and blacken objects,
// and have work to do, run idle-time marking rather than give up the P.
if gcBlackenEnabled != 0 && gcMarkWorkAvailable(pp) && gcController.addIdleMarkWorker() {
node := (*gcBgMarkWorkerNode)(gcBgMarkWorkerPool.pop())
if node != nil {
pp.gcMarkWorkerMode = gcMarkWorkerIdleMode
gp := node.gp.ptr()
trace := traceAcquire()
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.ok() {
trace.GoUnpark(gp, 0)
traceRelease(trace)
}
return gp, false, false
}
gcController.removeIdleMarkWorker()
}
...
}
写屏障
先前提到写屏障是保证 Go 语言并发标记安全不可或缺的技术,我们需要使用混合写屏障维护对象图的弱三色不变性。写屏障的实现需要编译器和运行时的共同协作。在 SSA 中间代码生成阶段,编译器会调用 ssa.writebarrier 函数在 Store、Move 和 Zero 操作中加入写屏障:
// cmd/compile/internal/ssa/writebarrier.go
// writebarrier pass inserts write barriers for store ops (Store, Move, Zero)
// when necessary (the condition above). It rewrites store ops to branches
// and runtime calls, like
//
// if writeBarrier.enabled {
// buf := gcWriteBarrier2() // Not a regular Go call
// buf[0] = val
// buf[1] = *ptr
// }
// *ptr = val
//
// A sequence of WB stores for many pointer fields of a single type will
// be emitted together, with a single branch.
func writebarrier(f *Func)
在生成 SSA 阶段,相关操作的写屏障就会被注入到操作位置。后当程序进入 GC 阶段的时候,setGCPhase 函数会修改全局变量 runtime.writeBarrier.enabled 的值,从而开启写屏障。所有相关的操作在执行阶段都会先执行 runtime.gcWriteBarrier2 执行写屏障操作:
// src/runtime/asm_amd64.s
TEXT runtime·gcWriteBarrier2<ABIInternal>(SB),NOSPLIT|NOFRAME,$0
MOVL $16, R11
JMP gcWriteBarrier<>(SB)
// src/runtime/asm_amd64.s
TEXT gcWriteBarrier<>(SB),NOSPLIT,$112
// Save the registers clobbered by the fast path. This is slightly
// faster than having the caller spill these.
MOVQ R12, 96(SP)
MOVQ R13, 104(SP)
retry:
// TODO: Consider passing g.m.p in as an argument so they can be shared
// across a sequence of write barriers.
MOVQ g_m(R14), R13
MOVQ m_p(R13), R13
// Get current buffer write position.
MOVQ (p_wbBuf+wbBuf_next)(R13), R12 // original next position
ADDQ R11, R12 // new next position
// Is the buffer full?
CMPQ R12, (p_wbBuf+wbBuf_end)(R13)
JA flush
// Commit to the larger buffer.
MOVQ R12, (p_wbBuf+wbBuf_next)(R13)
// Make return value (the original next position)
SUBQ R11, R12
MOVQ R12, R11
// Restore registers.
MOVQ 96(SP), R12
MOVQ 104(SP), R13
RET
flush:
...
CALL runtime·wbBufFlush(SB)
...
JMP retry
- 函数获取当前 goroutine 的
m结构体指针,并从中获取p结构体指针,这个p包含了写屏障缓冲区的信息。 - 通过
p结构体中的wbBuf_next字段获取当前缓冲区写入位置R12,然后将R11(缓冲区所需大小)加到R12上,计算出新的写入位置。 - 如果新的写入位置超出了缓冲区的末尾,函数会调用
flush子流程来刷写缓冲区的内容。 - 如果没有超出缓冲区末尾,函数会更新缓冲区的写入位置,并将原始下一个位置减去
R11的结果(即缓冲区开始的位置)存入R11,为调用者返回缓冲区空间的地址。
其中 Flush 子流程中的 runtime.wbBufFlush(SB) 函数调用就是用于将当前 P 中的写屏障缓冲刷写到 GC 的工作缓冲区中,并清空写屏障缓冲区,即在并发扫描阶段通知垃圾回收器堆上对象的指针变动。整个过程和 runtime.greyobject 十分相似。
// src/runtime/mwbbuf.go
func wbBufFlush() {
// Note: Every possible return from this function must reset
// the buffer's next pointer to prevent buffer overflow.
if getg().m.dying > 0 {
// We're going down. Not much point in write barriers
// and this way we can allow write barriers in the
// panic path.
getg().m.p.ptr().wbBuf.discard()
return
}
// Switch to the system stack so we don't have to worry about
// safe points.
systemstack(func() {
wbBufFlush1(getg().m.p.ptr())
})
}
func wbBufFlush1(pp *p) {
...
ptrs := pp.wbBuf.buf[:n]
...
for _, ptr := range ptrs {
if ptr < minLegalPointer {
// 过滤非堆上对象
continue
}
// 提取对象,跳过空指针
obj, span, objIndex := findObject(ptr, 0, 0)
if obj == 0 {
continue
}
mbits := span.markBitsForIndex(objIndex)
if mbits.isMarked() {
continue
}
mbits.setMarked()
// 标记内存页
arena, pageIdx, pageMask := pageIndexOf(span.base())
if arena.pageMarks[pageIdx]&pageMask == 0 {
atomic.Or8(&arena.pageMarks[pageIdx], pageMask)
}
if span.spanclass.noscan() {
gcw.bytesMarked += uint64(span.elemsize)
continue
}
ptrs[pos] = obj
pos++
}
// 将标记对象入队 GC 工作队列
gcw.putBatch(ptrs[:pos])
// 清空写屏障缓冲
pp.wbBuf.reset()
}
写屏障开启的时候,新创建的对象都会直接标记为黑色对象,该过程则由 runtime.gcmarknewobject 函数完成。
// src/runtime/malloc.go
// Allocate an object of size bytes.
// Small objects are allocated from the per-P cache's free lists.
// Large objects (> 32 kB) are allocated straight from the heap.
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
...
if gcphase != _GCoff {
gcmarknewobject(span, uintptr(x))
}
...
}
// src/runtime/mgcmark.go
func gcmarknewobject(span *mspan, obj uintptr) {
if useCheckmark { // The world should be stopped so this should not happen.
throw("gcmarknewobject called while doing checkmark")
}
// 标记对象
objIndex := span.objIndex(obj)
span.markBitsForIndex(objIndex).setMarked()
// 标记内存页
arena, pageIdx, pageMask := pageIndexOf(span.base())
if arena.pageMarks[pageIdx]&pageMask == 0 {
atomic.Or8(&arena.pageMarks[pageIdx], pageMask)
}
gcw := &getg().m.p.ptr().gcw
gcw.bytesMarked += uint64(span.elemsize)
}
并发扫描与标记
后台标记 Worker
前文提到,后台标记任务所执行的函数是 gcBgMarkWorker,其实现原理如下:
- 获取当前 P 和 goroutine 封装成
gcBgMarkWorkerNode结构,并主动调用gopark进入休眠状态。func gcBgMarkWorker() { gp := getg() // We pass node to a gopark unlock function, so it can't be on // the stack (see gopark). Prevent deadlock from recursively // starting GC by disabling preemption. gp.m.preemptoff = "GC worker init" node := new(gcBgMarkWorkerNode) gp.m.preemptoff = "" node.gp.set(gp) node.m.set(acquirem()) notewakeup(&work.bgMarkReady) for { // Go to sleep until woken by // gcController.findRunnableGCWorker. gopark(func(g *g, nodep unsafe.Pointer) bool { node := (*gcBgMarkWorkerNode)(nodep) if mp := node.m.ptr(); mp != nil { releasem(mp) } // Release this G to the pool. gcBgMarkWorkerPool.push(&node.node) // Note that at this point, the G may immediately be // rescheduled and may be running. return true }, unsafe.Pointer(node), waitReasonGCWorkerIdle, traceBlockSystemGoroutine, 0) ... } - 被调度器唤醒执行,检查当前环境是否符合继续执行的条件。
- 根据 P 上的
gcMarkWorkerMode模式决定扫描任务的策略。func gcBgMarkWorker() { for { ... systemstack(func() { casGToWaiting(gp, _Grunning, waitReasonGCWorkerActive) switch pp.gcMarkWorkerMode { default: throw("gcBgMarkWorker: unexpected gcMarkWorkerMode") case gcMarkWorkerDedicatedMode: gcDrainMarkWorkerDedicated(&pp.gcw, true) if gp.preempt { // We were preempted. This is // a useful signal to kick // everything out of the run // queue so it can run // somewhere else. if drainQ, n := runqdrain(pp); n > 0 { lock(&sched.lock) globrunqputbatch(&drainQ, int32(n)) unlock(&sched.lock) } } // Go back to draining, this time // without preemption. gcDrainMarkWorkerDedicated(&pp.gcw, false) case gcMarkWorkerFractionalMode: gcDrainMarkWorkerFractional(&pp.gcw) case gcMarkWorkerIdleMode: gcDrainMarkWorkerIdle(&pp.gcw) } casgstatus(gp, _Gwaiting, _Grunning) }) } }
需要注意的是,gcMarkWorkerDedicatedMode模式的任务是不能被抢占的,为了减少额外开销,第一次调用runtime.gcDrain时是允许抢占的,但是一旦处理器被抢占,当前 Goroutine 会将处理器上的所有可运行的 Goroutine 转移至全局队列中,并再次执行gcDrainMarkWorkerDedicated,且设置为不允许抢占,保证垃圾回收占用的 CPU 资源。 - 当所有的后台工作任务都陷入等待并且没有剩余工作时,就认为该轮垃圾回收的标记阶段结束了,这时会调用
runtime.gcMarkDone,表示并发标记完成。func gcBgMarkWorker() { for { ... // Was this the last worker and did we run out // of work? incnwait := atomic.Xadd(&work.nwait, +1) if incnwait > work.nproc { println("runtime: p.gcMarkWorkerMode=", pp.gcMarkWorkerMode, "work.nwait=", incnwait, "work.nproc=", work.nproc) throw("work.nwait > work.nproc") } // We'll releasem after this point and thus this P may run // something else. We must clear the worker mode to avoid // attributing the mode to a different (non-worker) G in // traceGoStart. pp.gcMarkWorkerMode = gcMarkWorkerNotWorker // If this worker reached a background mark completion // point, signal the main GC goroutine. if incnwait == work.nproc && !gcMarkWorkAvailable(nil) { // We don't need the P-local buffers here, allow // preemption because we may schedule like a regular // goroutine in gcMarkDone (block on locks, etc). releasem(node.m.ptr()) node.m.set(nil) gcMarkDone() } } }
GC Work
gcWork 是调用 gcDrain 时传入的参数,gcWork 为垃圾回收器提供了生产和消费垃圾回收任务的接口。
type gcWork struct {
// wbuf1 和 wbuf2 是主工作缓冲区和辅工作缓冲区。
wbuf1, wbuf2 *workbuf
// 当前 gcWork 上标黑的字节数
bytesMarked uint64
// 堆扫描工作执行量
heapScanWork int64
// flushedWork 用于标记非空工作缓冲是否被刷到全局工作列表中。
flushedWork bool
}
其中最主要的参数就是 wbuf1 和 wbuf2 两个工作缓冲区。当进行标记时,会将需要扫描的对象插入到主缓冲区中(包括从根出发扫描到的对象和操作指针触发的写屏障操作的对象),一旦主缓冲区空间不足或者没有对象,会触发主备缓冲区的切换;而当两个缓冲区空间都不足时,就会将缓冲区中的工作刷写到全局任务列表中,重新获取新的空缓冲区。而消费端也会不断扫描缓冲区中的对象,如果缓冲区为空,则会从全局工作队列中拉取满缓冲区以供消费标记。这种设计使得生产和消费有了一个缓冲区的滞后值,从而将获取或刷写工作缓冲区的成本摊销到至少一个工作缓冲区上,并减少了全局工作列表的争抢。
扫描对象
对象扫描通过调用 gcDrain 函数完成,通过传入不同的 gcDrainFlags 选择对应的扫描策略。
// gcDrainMarkWorkerIdle is a wrapper for gcDrain that exists to better account
// mark time in profiles.
func gcDrainMarkWorkerIdle(gcw *gcWork) {
gcDrain(gcw, gcDrainIdle|gcDrainUntilPreempt|gcDrainFlushBgCredit)
}
// gcDrainMarkWorkerDedicated is a wrapper for gcDrain that exists to better account
// mark time in profiles.
func gcDrainMarkWorkerDedicated(gcw *gcWork, untilPreempt bool) {
flags := gcDrainFlushBgCredit
if untilPreempt {
flags |= gcDrainUntilPreempt
}
gcDrain(gcw, flags)
}
// gcDrainMarkWorkerFractional is a wrapper for gcDrain that exists to better account
// mark time in profiles.
func gcDrainMarkWorkerFractional(gcw *gcWork) {
gcDrain(gcw, gcDrainFractional|gcDrainUntilPreempt|gcDrainFlushBgCredit)
}
func gcDrain(gcw *gcWork, flags gcDrainFlags) {
...
// checkWork is the scan work before performing the next
// self-preempt check.
checkWork := int64(1<<63 - 1)
var check func() bool
if flags&(gcDrainIdle|gcDrainFractional) != 0 {
checkWork = initScanWork + drainCheckThreshold
if idle {
check = pollWork
} else if flags&gcDrainFractional != 0 {
check = pollFractionalWorkerExit
}
}
...
}
gcDrainUntilPreempt:标记当前 worker 可被抢占,当 Goroutine 的preempt字段被设置成 true 时返回;gcDrainIdle:标记当前 worker 为空闲时运行 worker。调用runtime.pollWork检查,当处理器上包含其他待执行 Goroutine 时返回;// pollWork reports whether there is non-background work this P could // be doing. This is a fairly lightweight check to be used for // background work loops, like idle GC. It checks a subset of the // conditions checked by the actual scheduler. func pollWork() bool { if sched.runqsize != 0 { return true } p := getg().m.p.ptr() if !runqempty(p) { return true } if netpollinited() && netpollAnyWaiters() && sched.lastpoll.Load() != 0 { if list, delta := netpoll(0); !list.empty() { injectglist(&list) netpollAdjustWaiters(delta) return true } } return false }gcDrainFractional:标记当前 worker 为 Fractional worker。调用runtime.pollFractionalWorkerExit检查,当 CPU 占用率超过阈值fractionalUtilizationGoal的 120% 时返回;gcDrainFlushBgCredit:调用runtime.gcFlushBgCredit计算后台完成的标记任务量以减少并发标记期间的辅助垃圾回收的用户程序的工作量;
func gcFlushBgCredit(scanWork int64) {
if work.assistQueue.q.empty() {
// Fast path; there are no blocked assists. There's a
// small window here where an assist may add itself to
// the blocked queue and park. If that happens, we'll
// just get it on the next flush.
gcController.bgScanCredit.Add(scanWork)
return
}
}
完成策略相关的配置后,就会开始扫描全局 work 对象中的根对象。
func gcDrain(gcw *gcWork, flags gcDrainFlags) {
...
// Drain root marking jobs.
if work.markrootNext < work.markrootJobs {
// Stop if we're preemptible, if someone wants to STW, or if
// someone is calling forEachP.
for !(gp.preempt && (preemptible || sched.gcwaiting.Load() || pp.runSafePointFn != 0)) {
job := atomic.Xadd(&work.markrootNext, +1) - 1
if job >= work.markrootJobs {
break
}
markroot(gcw, job, flushBgCredit)
// 检查是否需要退出
if check != nil && check() {
goto done
}
}
}
...
}
扫描根对象需要使用 runtime.markroot,该函数会扫描缓存、数据段、存放全局变量和静态变量的 BSS 段以及 Goroutine 的栈内存;一旦完成了对根对象的扫描,就开始完成堆的标记任务。
func gcDrain(gcw *gcWork, flags gcDrainFlags) {
...
for !(gp.preempt && (preemptible || sched.gcwaiting.Load() || pp.runSafePointFn != 0)) {
// Try to keep work available on the global queue. We used to
// check if there were waiting workers, but it's better to
// just keep work available than to make workers wait. In the
// worst case, we'll do O(log(_WorkbufSize)) unnecessary
// balances.
if work.full == 0 {
gcw.balance()
}
b := gcw.tryGetFast()
if b == 0 {
b = gcw.tryGet()
if b == 0 {
// Flush the write barrier
// buffer; this may create
// more work.
wbBufFlush()
b = gcw.tryGet()
}
}
if b == 0 {
// Unable to get work.
break
}
scanobject(b, gcw)
// Flush background scan work credit to the global
// account if we've accumulated enough locally so
// mutator assists can draw on it.
if gcw.heapScanWork >= gcCreditSlack {
gcController.heapScanWork.Add(gcw.heapScanWork)
if flushBgCredit {
gcFlushBgCredit(gcw.heapScanWork - initScanWork)
initScanWork = 0
}
checkWork -= gcw.heapScanWork
gcw.heapScanWork = 0
if checkWork <= 0 {
checkWork += drainCheckThreshold
if check != nil && check() {
break
}
}
}
}
...
}
当前 Goroutine 会开始从本地和全局的工作缓存池中获取待执行的任务,获取到的任务会使用 runtime.scanobject 函数进行对象扫描,该函数会从传入的位置开始扫描,扫描会进行大对象拆分,加快并发扫描速度。
func scanobject(b uintptr, gcw *gcWork) {
...
// 将大于 128kb 的对象扫描任务进行分拆,
// 同时将分拆出来的任务入任务队列。
if n > maxObletBytes {
// Large object. Break into oblets for better
// parallelism and lower latency.
if b == s.base() {
// Enqueue the other oblets to scan later.
// Some oblets may be in b's scalar tail, but
// these will be marked as "no more pointers",
// so we'll drop out immediately when we go to
// scan those.
for oblet := b + maxObletBytes; oblet < s.base()+s.elemsize; oblet += maxObletBytes {
if !gcw.putFast(oblet) {
gcw.put(oblet)
}
}
}
// Compute the size of the oblet. Since this object
// must be a large object, s.base() is the beginning
// of the object.
n = s.base() + s.elemsize - b
n = min(n, maxObletBytes)
if goexperiment.AllocHeaders {
tp = s.typePointersOfUnchecked(s.base())
tp = tp.fastForward(b-tp.addr, b+n)
}
} else {
if goexperiment.AllocHeaders {
tp = s.typePointersOfUnchecked(b)
}
}
...
}
随后会沿着对象的指针不断扫描,调用 runtime.greyobject 为找到的活跃对象上色。
func scanobject(b uintptr, gcw *gcWork) {
...
for {
var addr uintptr
if goexperiment.AllocHeaders {
if tp, addr = tp.nextFast(); addr == 0 {
if tp, addr = tp.next(b + n); addr == 0 {
break
}
}
} else {
if hbits, addr = hbits.nextFast(); addr == 0 {
if hbits, addr = hbits.next(); addr == 0 {
break
}
}
}
// Keep track of farthest pointer we found, so we can
// update heapScanWork. TODO: is there a better metric,
// now that we can skip scalar portions pretty efficiently?
scanSize = addr - b + goarch.PtrSize
// Work here is duplicated in scanblock and above.
// If you make changes here, make changes there too.
obj := *(*uintptr)(unsafe.Pointer(addr))
// At this point we have extracted the next potential pointer.
// Quickly filter out nil and pointers back to the current object.
if obj != 0 && obj-b >= n {
// Test if obj points into the Go heap and, if so,
// mark the object.
//
// Note that it's possible for findObject to
// fail if obj points to a just-allocated heap
// object because of a race with growing the
// heap. In this case, we know the object was
// just allocated and hence will be marked by
// allocation itself.
if obj, span, objIndex := findObject(obj, b, addr-b); obj != 0 {
greyobject(obj, b, addr-b, span, gcw, objIndex)
}
}
}
...
}
被扫描到的活跃对象又会进入到任务队列中等待扫描。
func greyobject(obj, base, off uintptr, span *mspan, gcw *gcWork, objIndex uintptr) {
...
// 检查对象是否已被标记
// 已标记则证明被扫描过,直接返回
if mbits.isMarked() {
return
}
mbits.setMarked()
// 标记内存页
arena, pageIdx, pageMask := pageIndexOf(span.base())
if arena.pageMarks[pageIdx]&pageMask == 0 {
atomic.Or8(&arena.pageMarks[pageIdx], pageMask)
}
...
sys.Prefetch(obj)
// 将对象入工作队列
if !gcw.putFast(obj) {
gcw.put(obj)
}
}
当本轮的扫描因为外部条件变化而中断或本轮扫描任务完成时,gcDrain 会通过 runtime.gcFlushBgCredit 记录这次扫描的内存字节数用于减少辅助标记的工作量。
func gcDrain(gcw *gcWork, flags gcDrainFlags) {
...
done:
// Flush remaining scan work credit.
if gcw.heapScanWork > 0 {
gcController.heapScanWork.Add(gcw.heapScanWork)
if flushBgCredit {
gcFlushBgCredit(gcw.heapScanWork - initScanWork)
}
gcw.heapScanWork = 0
}
}
辅助标记
为了保证用户程序在 GC 期间分配内存的速度不超出后台标记的速度,Go 在运行时引入了辅助标记机制,该辅助标记机制的原则是当前 Goroutine 在运行时调用 mallocgc 分配多少内存就需要完成多少标记任务。每一个 Goroutine 都持有 gcAssistBytes 字段,这个字段存储了当前 Goroutine 辅助标记的对象字节数。在并发标记阶段期间,当 Goroutine 调用 runtime.mallocgc 分配新对象时,该函数会检查申请内存的 Goroutine 是否有足够的辅助额度进行扣减:
// src/runtime/malloc.go
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
...
// assistG is the G to charge for this allocation, or nil if
// GC is not currently active.
assistG := deductAssistCredit(size)
...
}
// deductAssistCredit reduces the current G's assist credit
// by size bytes, and assists the GC if necessary.
//
// Caller must be preemptible.
//
// Returns the G for which the assist credit was accounted.
func deductAssistCredit(size uintptr) *g {
var assistG *g
if gcBlackenEnabled != 0 {
// Charge the current user G for this allocation.
assistG = getg()
if assistG.m.curg != nil {
assistG = assistG.m.curg
}
// Charge the allocation against the G. We'll account
// for internal fragmentation at the end of mallocgc.
assistG.gcAssistBytes -= int64(size)
if assistG.gcAssistBytes < 0 {
// This G is in debt. Assist the GC to correct
// this before allocating. This must happen
// before disabling preemption.
gcAssistAlloc(assistG)
}
}
return assistG
}
不够额度的 goroutine 会被强制调用 runtime.gcAssistAlloc 函数还清负债。
// gcAssistAlloc performs GC work to make gp's assist debt positive.
// gp must be the calling user goroutine.
//
// This must be called with preemption enabled.
func gcAssistAlloc(gp *g)
每个 Goroutine 持有的 gcAssistBytes 表示当前协程辅助标记的字节数,全局垃圾回收控制器持有的 bgScanCredit 表示后台标记的字节数,当本地 Goroutine 分配了较多对象时,可以优先使用后台标记产生的信用额 bgScanCredit 偿还。
func gcAssistAlloc(gp *g) {
...
bgScanCredit := gcController.bgScanCredit.Load()
stolen := int64(0)
if bgScanCredit > 0 {
if bgScanCredit < scanWork {
stolen = bgScanCredit
gp.gcAssistBytes += 1 + int64(assistBytesPerWork*float64(stolen))
} else {
stolen = scanWork
gp.gcAssistBytes += debtBytes
}
gcController.bgScanCredit.Add(-stolen)
scanWork -= stolen
// 从 bgScanCredit 偷取了足够的额度
if scanWork == 0 {
if enteredMarkAssistForTracing {
...
gp.inMarkAssist = false
...
} else {
gp.inMarkAssist = false
}
}
return
}
...
}
但由于 gcAssistAlloc 是并发执行且没有加锁,所以 bgScanCredit 可能会被更新成负值,后续的偷取将会失败,直到 bgScanCredit 在后台标记的持续工作下重回正值。
如果 bgScanCredit 不足以覆盖债务,运行时会在系统栈中调用 runtime.gcAssistAlloc1 函数执行标记任务,会进一步调用 runtime.gcDrainN 函数完成指定数量的标记任务并返回:
func gcAssistAlloc(gp *g) {
...
// Perform assist work
systemstack(func() {
gcAssistAlloc1(gp, scanWork)
// The user stack may have moved, so this can't touch
// anything on it until it returns from systemstack.
})
...
}
func gcAssistAlloc1(gp *g, scanWork int64) {
...
// gcDrainN requires the caller to be preemptible.
casGToWaiting(gp, _Grunning, waitReasonGCAssistMarking)
// drain own cached work first in the hopes that it
// will be more cache friendly.
gcw := &getg().m.p.ptr().gcw
workDone := gcDrainN(gcw, scanWork)
casgstatus(gp, _Gwaiting, _Grunning)
assistBytesPerWork := gcController.assistBytesPerWork.Load()
gp.gcAssistBytes += 1 + int64(assistBytesPerWork*float64(workDone))
...
}
所完成的辅助标记任务将被计入 gcAssistBytes 中,用于债务的抵扣。如果在完成标记辅助任务后,当前 Goroutine 仍然入不敷出,则根据情况执行不同的操作:
- 有 Goroutine 抢占执行权限,则让出当前执行权,调度发起抢占的 Goroutine
- 没有 Goroutine 发起抢占,那么将执行
runtime.gcParkAssist函数尝试将当前 Goroutine 陷入休眠、加入全局的辅助标记队列并等待后台标记任务的唤醒。func gcParkAssist() bool { lock(&work.assistQueue.lock) // 如果标记阶段结束,则直接返回成功。 if atomic.Load(&gcBlackenEnabled) == 0 { unlock(&work.assistQueue.lock) return true } gp := getg() oldList := work.assistQueue.q work.assistQueue.q.pushBack(gp) // 再次检查 bgScanCredit 是否回正, // 如果回正则将当前 goroutine 从辅助队列中取出并直接返回 false, // 当前 goroutine 会重新尝试相同流程从 bgScanCredit 中偷取信用额。 // 该机制避免多个辅助标记 goroutine 在同时结束后对 bgScanCredit 争抢。 if gcController.bgScanCredit.Load() > 0 { work.assistQueue.q = oldList if oldList.tail != 0 { oldList.tail.ptr().schedlink.set(nil) } unlock(&work.assistQueue.lock) return false } // 休眠 goroutine,等待辅助标记调度唤醒。 goparkunlock(&work.assistQueue.lock, waitReasonGCAssistWait, traceBlockGCMarkAssist, 2) return true }
先前大量提到的 bgScanCredit 主要由以下函数增加,分别在 runtime.markroot 和 runtime.gcDrain 在完成标记任务后调用:
func gcFlushBgCredit(scanWork int64) {
if work.assistQueue.q.empty() {
// Fast path; there are no blocked assists. There's a
// small window here where an assist may add itself to
// the blocked queue and park. If that happens, we'll
// just get it on the next flush.
gcController.bgScanCredit.Add(scanWork)
return
}
assistBytesPerWork := gcController.assistBytesPerWork.Load()
scanBytes := int64(float64(scanWork) * assistBytesPerWork)
lock(&work.assistQueue.lock)
for !work.assistQueue.q.empty() && scanBytes > 0 {
gp := work.assistQueue.q.pop()
// Note that gp.gcAssistBytes is negative because gp
// is in debt. Think carefully about the signs below.
if scanBytes+gp.gcAssistBytes >= 0 {
// Satisfy this entire assist debt.
scanBytes += gp.gcAssistBytes
gp.gcAssistBytes = 0
// It's important that we *not* put gp in
// runnext. Otherwise, it's possible for user
// code to exploit the GC worker's high
// scheduler priority to get itself always run
// before other goroutines and always in the
// fresh quantum started by GC.
ready(gp, 0, false)
} else {
// Partially satisfy this assist.
gp.gcAssistBytes += scanBytes
scanBytes = 0
// As a heuristic, we move this assist to the
// back of the queue so that large assists
// can't clog up the assist queue and
// substantially delay small assists.
work.assistQueue.q.pushBack(gp)
break
}
}
if scanBytes > 0 {
// Convert from scan bytes back to work.
assistWorkPerByte := gcController.assistWorkPerByte.Load()
scanWork = int64(float64(scanBytes) * assistWorkPerByte)
gcController.bgScanCredit.Add(scanWork)
}
unlock(&work.assistQueue.lock)
}
gcFlushBgCredit 的逻辑也比较直接,在辅助队列中不存在等待的 Goroutine 时,则将完成标记任务获取到的积分添加到 bgScanCredit 中,否则就依次偿还辅助队列中 goroutine 缺少的积分,直到积分耗尽,或辅助队列为空,并剩余的添加到 bgScanCredit。
用户程序辅助标记的核心目的是避免用户程序分配内存影响垃圾收集器完成标记工作的期望时间,它通过维护账户体系保证用户程序不会对垃圾收集造成过多的负担,一旦用户程序分配了大量的内存,该用户程序就会通过辅助标记的方式平衡账本,这个过程会在最后达到相对平衡,保证标记任务在到达期望堆大小时完成。
结束标记
当所有 Worker 的本地任务都完成并且不存在其他 Worker 时,后台并发任务或者辅助标记的 Goroutine 会调用 runtime.gcMarkDone 通知垃圾收集器。当所有可达对象都被标记后,该函数会将垃圾收集的状态切换至 _GCmarktermination;如果本地队列中仍然存在待处理的任务,当前方法会将所有的任务加入全局队列并等待其他 Goroutine 完成处理:
func gcBgMarkWorker() {
...
for {
...
// Was this the last worker and did we run out
// of work?
incnwait := atomic.Xadd(&work.nwait, +1)
if incnwait > work.nproc {
println("runtime: p.gcMarkWorkerMode=", pp.gcMarkWorkerMode,
"work.nwait=", incnwait, "work.nproc=", work.nproc)
throw("work.nwait > work.nproc")
}
// We'll releasem after this point and thus this P may run
// something else. We must clear the worker mode to avoid
// attributing the mode to a different (non-worker) G in
// traceGoStart.
pp.gcMarkWorkerMode = gcMarkWorkerNotWorker
// If this worker reached a background mark completion
// point, signal the main GC goroutine.
if incnwait == work.nproc && !gcMarkWorkAvailable(nil) {
// We don't need the P-local buffers here, allow
// preemption because we may schedule like a regular
// goroutine in gcMarkDone (block on locks, etc).
releasem(node.m.ptr())
node.m.set(nil)
gcMarkDone()
}
}
}
func gcAssistAlloc(gp *g) {
...
retry:
...
// Perform assist work
systemstack(func() {
gcAssistAlloc1(gp, scanWork)
// The user stack may have moved, so this can't touch
// anything on it until it returns from systemstack.
})
completed := gp.param != nil
gp.param = nil
if completed {
gcMarkDone()
}
...
}
func gcMarkDone() {
...
top:
// 再次检查当前的 GC 状态,是否有剩余 GC Work,全局工作队列是否清空
if !(gcphase == _GCmark && work.nwait == work.nproc && !gcMarkWorkAvailable(nil)) {
semrelease(&work.markDoneSema)
return
}
// 获取 forEachP 所需的全局信号量
semacquire(&worldsema)
// Flush all local buffers and collect flushedWork flags.
gcMarkDoneFlushed = 0
forEachP(waitReasonGCMarkTermination, func(pp *p) {
// 遍历 P,将写屏障缓存刷写到任务队列中,清空写屏障缓存
wbBufFlush1(pp)
// Flush the gcWork, since this may create global work
// and set the flushedWork flag.
//
// TODO(austin): Break up these workbufs to
// better distribute work.
pp.gcw.dispose()
// Collect the flushedWork flag.
if pp.gcw.flushedWork {
atomic.Xadd(&gcMarkDoneFlushed, 1)
pp.gcw.flushedWork = false
}
})
if gcMarkDoneFlushed != 0 {
// More grey objects were discovered since the
// previous termination check, so there may be more
// work to do. Keep going. It's possible the
// transition condition became true again during the
// ragged barrier, so re-check it.
semrelease(&worldsema)
goto top
}
...
}
在函数 gcMarkDone 中,forEachP 是一个遍历所有处理器(P)的函数,它接受一个闭包函数作为参数,并为运行时中的每个 P 执行这个闭包函数。在这个上下文中,闭包函数做了以下几件事情:
- 刷新写屏障缓冲区 (
wbBufFlush1(pp)): 这是为了确保所有的写屏障缓冲区(由wbBuf管理)中积累的指针都被处理。写屏障缓冲区是用于标记阶段的,当一个指针值被更新时,旧的对象需要被标记为灰色,表示它们是待处理的。刷新这些缓冲区可以将这些对象添加到全局标记工作中。 - 处理 gcWork (
pp.gcw.dispose()): 这个调用会处理每个 P 上的本地gcWork,将任何剩余的本地标记工作推进到全局队列中,使得其他 P 可以接手这些工作。 - 收集
flushedWork标志:如果在刷新过程中发现了新的灰色对象(即新的标记工作),flushedWork标志会被设置为 true。这个标志表示在刷新本地工作之后,可能还有更多的工作要做。闭包内部,如果一个 P 的flushedWork是 true,那么它会将gcMarkDoneFlushed计数器增加 1,并将该 P 的flushedWork重置为 false。
如果 gcMarkDoneFlushed 不为零,这意味着在之前的标记终止检查之后,发现了更多的灰色对象,所以可能还有更多的工作要做,垃圾回收过程将不会停止,直到所有工作完成。这个闭包的作用是确保所有 P 的本地状态都被正确地处理和同步,以便垃圾回收器可以安全地前进到下一个阶段。
当所有条件都满足后,即所有标记工作(本地、全局)都已经完成的情况下,再次启动 STW,完成收尾工作。
func gcMarkDone() {
...
top:
...
var stw worldStop
systemstack(func() {
stw = stopTheWorldWithSema(stwGCMarkTerm)
})
restart := false
systemstack(func() {
for _, p := range allp {
wbBufFlush1(p)
if !p.gcw.empty() {
restart = true
break
}
}
})
if restart {
getg().m.preemptoff = ""
systemstack(func() {
now := startTheWorldWithSema(0, stw)
work.pauseNS += now - stw.start
})
semrelease(&worldsema)
goto top
}
gcComputeStartingStackSize()
// Disable assists and background workers. We must do
// this before waking blocked assists.
atomic.Store(&gcBlackenEnabled, 0)
// Notify the CPU limiter that GC assists will now cease.
gcCPULimiter.startGCTransition(false, now)
// Wake all blocked assists. These will run when we
// start the world again.
gcWakeAllAssists()
// Likewise, release the transition lock. Blocked
// workers and assists will run when we start the
// world again.
semrelease(&work.markDoneSema)
// In STW mode, re-enable user goroutines. These will be
// queued to run after we start the world.
schedEnableUser(true)
// endCycle depends on all gcWork cache stats being flushed.
// The termination algorithm above ensured that up to
// allocations since the ragged barrier.
gcController.endCycle(now, int(gomaxprocs), work.userForced)
// Perform mark termination. This will restart the world.
gcMarkTermination(stw)
}
- 再次刷写所有 P 的写屏障缓冲,如果仍存在待完成的标记任务,则重复检查直到标记任务结束。这个步骤是为了避免先前步骤中为了完成所有写屏障任务,又再次触发了写屏障导致的任务遗漏。
- 确认没有任务,调用
gcComputeStartingStackSize计算启动新 goroutine 时使用的默认栈大小。 - 修改全局变量
gcBlackenEnabled禁用后台标记和辅助标记 Worker。 - 通知
gcCPULimiter有关 GC 阶段的转变,结束相关的 CPU 限制。 - 唤醒辅助队列中剩余的 Goroutine。
- 将所有用户程序启动的 Goroutine 加入队列,等待 STW 结束后重新调度。
- 调用
gcController.endCycle,修改 GC 控制器中的一些必要参数,标志此轮 GC 循环结束。 - 调用
gcMarkTermination进入标记终止阶段,包括修改 GC 状态,执行垃圾回收,关闭写屏障,结束 STW 恢复调度,清理 P.mcache,更新 GC 相关统计数据等。
func gcMarkTermination(stw worldStop) {
setGCPhase(_GCmarktermination)
...
systemstack(func() {
gcMark(startTime)
...
})
var stwSwept bool
systemstack(func() {
...
// marking is complete so we can turn the write barrier off
setGCPhase(_GCoff)
stwSwept = gcSweep(work.mode)
})
...
// Update GC trigger and pacing, as well as downstream consumers
// of this pacing information, for the next cycle.
systemstack(gcControllerCommit)
...
systemstack(func() {
...
startTheWorldWithSema(now, stw)
})
...
forEachP(waitReasonFlushProcCaches, func(pp *p) {
pp.mcache.prepareForSweep()
if pp.status == _Pidle {
systemstack(func() {
lock(&mheap_.lock)
pp.pcache.flush(&mheap_.pages)
unlock(&mheap_.lock)
})
}
pp.pinnerCache = nil
})
...
semrelease(&worldsema)
semrelease(&gcsema)
...
}
垃圾回收
垃圾收集的清理中包含对象回收器(Reclaimer)和内存单元回收器,这两种回收器使用不同的算法清理堆内存:
- 对象回收器在内存管理单元中查找并释放未被标记的对象,但是如果
runtime.mspan中的所有对象都没有被标记,整个单元就会被直接回收,该过程会被runtime.mcentral.cacheSpan或者runtime.sweepone异步触发; - 内存单元回收器会在内存中查找所有的对象都未被标记的
runtime.mspan,该过程会被runtime.mheap.reclaim触发;
runtime.sweepone 是我们在垃圾收集过程中经常会见到的函数,它会在堆内存中查找待清理的内存管理单元:
// src/runtime/mgcsweep.go
func sweepone() uintptr {
...
// Find a span to sweep.
npages := ^uintptr(0)
var noMoreWork bool
for {
s := mheap_.nextSpanForSweep()
if s == nil {
noMoreWork = sweep.active.markDrained()
break
}
if state := s.state.get(); state != mSpanInUse {
// This can happen if direct sweeping already
// swept this span, but in that case the sweep
// generation should always be up-to-date.
if !(s.sweepgen == sl.sweepGen || s.sweepgen == sl.sweepGen+3) {
print("runtime: bad span s.state=", state, " s.sweepgen=", s.sweepgen, " sweepgen=", sl.sweepGen, "\n")
throw("non in-use span in unswept list")
}
continue
}
if s, ok := sl.tryAcquire(s); ok {
// Sweep the span we found.
npages = s.npages
if s.sweep(false) {
// Whole span was freed. Count it toward the
// page reclaimer credit since these pages can
// now be used for span allocation.
mheap_.reclaimCredit.Add(npages)
} else {
// Span is still in-use, so this returned no
// pages to the heap and the span needs to
// move to the swept in-use list.
npages = 0
}
break
}
}
sweep.active.end(sl)
...
}
通过 mheap_.nextSpanForSweep() 查找下一个需要清扫的 span。随后对找到的 span 执行清扫操作。如果 span 被完全清扫(即没有存活对象),则会将它的页数计入内存回收的统计;如果 span 仍在使用(即有存活对象),则不会回收页数,并需要将该 span 移动到已清扫的列表中。通过 tryAcquire 进行原子操作修改内存页状态以获取内存页的控制权。
// src/runtime/mgcsweep.go
func (l *sweepLocker) tryAcquire(s *mspan) (sweepLocked, bool) {
if !l.valid {
throw("use of invalid sweepLocker")
}
// Check before attempting to CAS.
if atomic.Load(&s.sweepgen) != l.sweepGen-2 {
return sweepLocked{}, false
}
// Attempt to acquire sweep ownership of s.
if !atomic.Cas(&s.sweepgen, l.sweepGen-2, l.sweepGen-1) {
return sweepLocked{}, false
}
return sweepLocked{s}, true
}
查找内存管理单元时会通过 state 和 sweepgen 两个字段判断当前单元是否需要处理。如果内存单元的 sweepgen 等于 mheap.sweepgen - 2,那么意味着当前单元需要清理,如果等于 mheap.sweepgen - 1,那么当前管理单元就正在清理。
// src/runtime/mheap.go
type mspan struct {
// sweep generation:
// if sweepgen == h->sweepgen - 2, the span needs sweeping
// if sweepgen == h->sweepgen - 1, the span is currently being swept
// if sweepgen == h->sweepgen, the span is swept and ready to use
// if sweepgen == h->sweepgen + 1, the span was cached before sweep began and is still cached, and needs sweeping
// if sweepgen == h->sweepgen + 3, the span was swept and then cached and is still cached
// h->sweepgen is incremented by 2 after every GC
sweepgen uint32
}
最后通过调用 sweep(false) 对内存页进行清理。
func (sl *sweepLocked) sweep(preserve bool) bool
- 释放未标记的对象:迭代 span 中的所有对象,对于那些没有被标记为存活的对象,即在标记阶段未被确认为需要保留的对象,将它们的内存释放回内存池中。
- 处理 Finalizer:如果有对象设置了 Finalizer,并且这些对象未被标记为存活,那么在回收它们的内存之前,需要先执行它们的 Finalizer。
- 更新 span 状态:清扫完毕后,该函数将更新 span 的状态。如果
preserve参数为 false 且 span 中所有对象都已经死亡(即没有存活的对象),那么这个 span 可以被完全释放,回到堆中以供未来分配。 - 保留逻辑:如果
preserve参数为 true,无论 span 中是否有存活的对象,都不会将其返回到堆中。这在某些情况下使用,例如在 span 不能立即返回到堆中进行再分配的情况下。
总结
Go 语言垃圾收集器的实现非常复杂,借助诸多机制保证垃圾回收的准确性和回收性能,同时涉及了大量的底层操作。种种因素叠加下使得垃圾回收器成为 Go 语言体系中最复杂的模块。
